클라우드 컴퓨팅 정리
업데이트:
클라우드 컴퓨팅 과목 시험을 위한 정리해둔 내용입니다.
Cloud Computing
분산 시스템이란
유저에게 하나의 coherent system으로 보이는 독립적인 컴퓨터들의 집합이다.
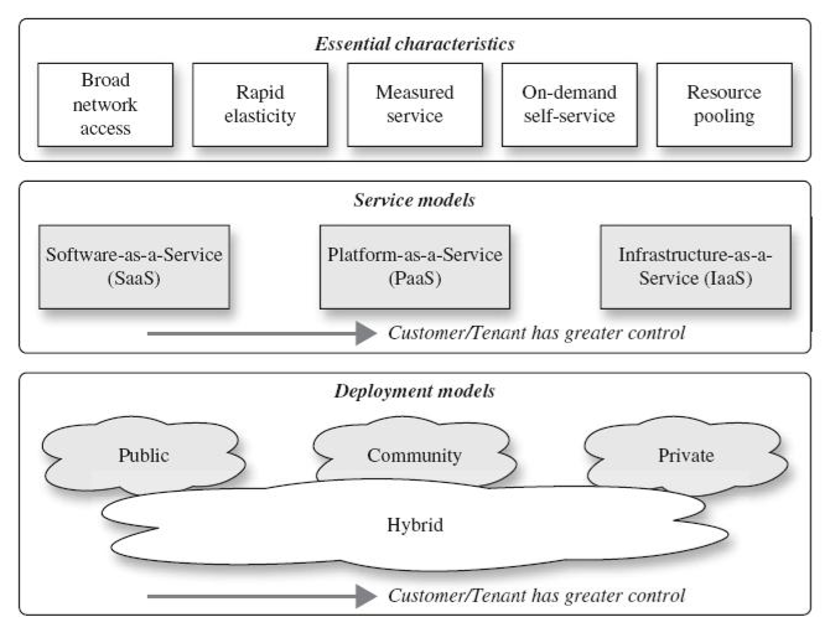
클라우드 컴퓨팅 특성
- on-demand self-service
- 사람과의 상호작용 없이 자동으로 필요에 따라 서비스한다
- broad network access
- 수용력
- 표준 메커니즘을 통해 접근
- 네트워크를 통해 접근
- resource pooling
- 다수 고객에게 서비스하기 위함
- rapid elasticity.
- 빠르게 scale out 하고 빠르게 릴리즈한다
- scale out : 수평 확장. 서버의 수를 늘려 처리 능력을 향상시킨다.
- scale up : 수직 확장. 서버의 하드웨어 성능 자체를 높이는 것
- 빠르게 scale out 하고 빠르게 릴리즈한다
- measured services 쓴만큼 내세요!
- 자원 사용은 모니터, 제어, 리포트된다. 제공자와 소비자에게 투명성을 제공한다.
클라우드 서비스 모델
- Cloud Software-as-a-Service (SaaS)
- 클라우드 환경에서 실행되는 제공자의 애플리케이션을 사용가능
- 책임과 권한 : Application level
- Cloud Platform-as-a-Service (Paas)
- 제공자가 지정해준 프로그래밍 언어와 툴로 소비자가 만든 클라우드 환경 또는 어플리케이션을 배포가능
- 책임과 권한 : Application, Middleware(애매하다)
- Cloud Infrastructure-as-a-Service (IaaS) 하드웨어, 깡통
- **스토리지, 네트워크 등 다른 기본적인 컴퓨팅 자원을 공급한다 **
- 따라서 소비자는 OS와 어플리케이션을 포함해서 임의의 소프트웨어를 배포, 실행할 수 있다.
- 책임과 권한 : Application level, Middleware, Guest OS

- 클라우드 보안 관점
- 가용성이 상속적이라, 보안 이슈가 발생
컴파일: 사용자가 작성한 코드를 컴퓨터가 이해할 수 있는 언어로 번역하는 일
빌드: 컴파일된 코드를 실제 실행할 수 있는 상태로 만드는 일
배포: 빌드가 완성된 실행 가능한 파일을 사용자가 접근할 수 있는 환경에 배치시키는 일
혹은 컴파일을 포함해 war, jar 등의 실행 가능한 파일을 뽑아내기까지의 과정을 빌드한다고도 함.
배포(deployment) 모델
- private cloud : 특정 기업의 사람들만 사용할 수 있도록 설정
- 해당 조직또는 서드파티에 의해 관리됨
- community cloud : 같은 업종의 사람들이 같이 쓴다.
- 특정 커뮤니티나 조직에 의해 공유되는 클라우드 환경
- 보안, 정책, 복잡도 등 걱정거리도 공유한다.
- public cloud : 비용은 적게 들지만 보안이 취약하다
- 일반 사용자들이 사용할 수 있다.
- hybrid cloud : public + private
고성능(HP)과 고처리(HT)
-
HPC (High Performance Computing) : 주로 연산 목적, 빨리 끝내기만 하면 됨. 병렬 컴퓨터
-
HTC (High Throughput Computing) : 사용자의 요구를 얼만큼 많이 받을 수 있나? 처리량, 동시접속자수 중점
설계 목적
- efficiency
- dependability
- adaptation in the programming model
- flexibility in application deployment
컴퓨팅 패러다임 특성
- 중앙집중형 컴퓨팅
- 자원이 완전히 공유되고 단단히 묶여있다. 하나의 통합된 OS안에
- 병렬 컴퓨팅
- centralized shared memory(UMA)로 단단히 묶여있거나
- UMA : 프로세서가 공유메모리를 통해 통신. hot traffic
- distributed memory(NUMA)로 느슨히 묶여있다.
- NUMA : local memory를 이용함. traffic이 적어짐
- centralized shared memory(UMA)로 단단히 묶여있거나
- 분산 컴퓨팅
- 여러 자율적 컴퓨터가 message passing방식으로 통신한다.
- 클라우드 컴퓨팅
- centralized되거나 distribute된 큰 데이터센터의 물리적 또는 가상화된 자원
Scalable Computing Trends & New Paradigm
- 병렬화 단계
- bit-level 병렬화
- 명령 레벨 병렬화(ILP)
- 파이프라인, 슈퍼스칼라, 컴퓨팅, 멀티스레딩
- 데이터 레벨 병렬화 (DLP)
- SIMD(Single Instruction, Multiple Data) with 멀티코어 프로세서와 칩 멀티프로세서(CMP)
- 태스크 레벨 병렬화(TLP)
- 프로그래밍과 컴파일의 어려움. 멀티코어 CMP의 효율적 수행을 위함.
성능 척도(metrics)
Performance Metrics
- CPU 속도 MIPS와 네트워크 대역폭 Mbps
- 시스템 처리량
- MIPS에서, Tflops(tera floating point operation per second, TPS(transaction per second)
- 시스템 오버헤드
- job response time, 네트워크 지연, OS 부트 시간, 컴파일 시간, 입출력데이터율, runtime support system used
Dimensions of Scalability
- size
- 머신 사이즈가 증가함에 따라 높은 성능 또는 많은 기능성을 가진다
- 소프트웨어(업그레이드), 어플리케이션(problem size), 기술(시간, 공간, 이질성) 확장성
클러스터링
독립적인 컴퓨터들의 연결된 집합
- job level에서의 대량의 병렬화와 high availability(HA)
- cost-effectiveness, scalability, HA features
cluster vs MPP
- cluster
- memory, disk 등의 관점에서 각각의 머신이 독립적이다.
- 대규모 병렬 컴퓨터 Massivly Parallel Computer
- only one machine. 수천개의 CPU가 강하게 연결되있다.
- 이웃 프로세서 간 중간 결과를 빠른 속도로 교환
parallelism
job을 여러 task로 쪼갠다.
큰 문제를 작은 문제로 쪼개 해결. 각각의 문제는 동시에 해결된다.
- task parallelism
- data parallelism
- data partitions : 데이터를 여러 조각으로 나눈 다음 순환적으로 처리
- block : 각 스레드는 데이터의 한 부분만을 가진다.
- cyclic : 각 스레드는 데이터의 한 부분 이상을 가진다.
- data partitions : 데이터를 여러 조각으로 나눈 다음 순환적으로 처리
- GPU
- 상대적으로 가벼운 코어가 많은 아키텍처.
- data-parallel task에서 최적화. CPU보다 단순한 제어 로직
multicore, multithreading
- 작은 코어가 여러개 있음.
- 각 스레드는 고유의 명령 주소 카운터, register state를 가진다.
- 각 스레드는 독립적인 수행 경로를 가진다.
- 동일한 task를 thread 별로 다른 데이터를 다르게 처리할 수 있다 <- Core의 대기를 피할수 있다.
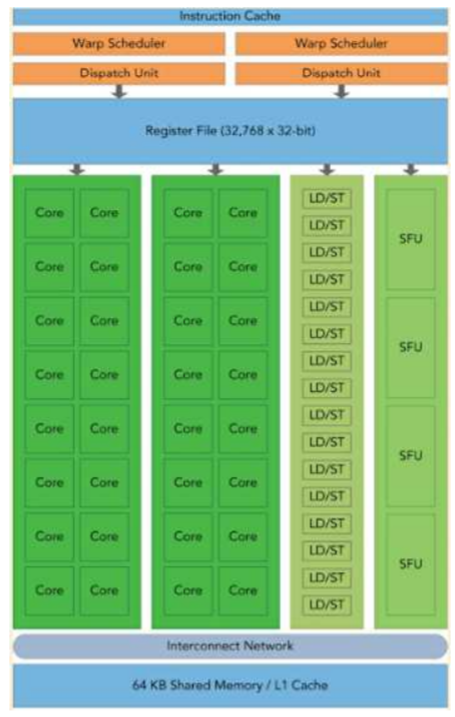
클러스터 구성(organization)
- Cluster Organization and Resource Sharing
- Shared-nothing : most used, with LAN
- Shared-disk : in small-scale clusters, hold ckpt files
- Shared memory : 잘 쓰지 않는다.
- Single-system Image feature
- single system : 하나의 시스템처럼 보인다.
- single control
- symmetry : 모든 노드가 동일하다. 바뀌어도 문제 없음
- location-transparent
- GPU
- CUDA
- Programming Structure
- GPU 메모리를 할당한다
- 데이터를 CPU에서 GPU메모리로 복제한다.
- CUDA 커널을 깨워 프로그램 특정 연산을 수행한다.
- GPU메모리의 데이터를 CPU메모리로 복제한다.
- GPU memory를 없앤다.
- Programming Structure
고가용성(HA)
- high availability through Redundancy
- RAS 요구(신뢰성, 가용성, serviceability)
- reliability : 얼마나 오랫동안 시스템이 breakdown 없이 작동하는가
- availability : system uptime의 비율
- serviceability : 하드웨어 소프트웨어 유지, 보수, 업그레이드.
- Redundancy Techniques
- MTTF를 높이기 위해
- Isolated Redundancy : 다양성을 높인다.
- primary와 backup은 같은 failure에 종속되어서는 안된다.
- N-version programming. 소프트웨어 신뢰성 향상을 위한.
- RAS 요구(신뢰성, 가용성, serviceability)
가상화
HW 가상화 / OS수준의 가상화.
- HW레벨 VMWare
- HW가동률을 업그레이드하기 위해. 여러 사용자가 동시에 Xen 하이퍼바이저 또는 다른 guest OS를 실행
- 장점 : 필요한 하드웨어 사양만 맞추면 어려움 없이 가상화
- 단점 : CPU나 메모리에 오버헤드 발생하여 가상머신 성능 저하
- OS 레벨 Docker
- 전통적 os(Linux)와 유저 어플리케이션 사이
- 싱글 물리 서버와 OS 인스턴스에 고립된 컨테이너를 만든다.
- 컨네이너 간 효율은 좋지만 보안에 약하다
- 장점 : CPU나 메모리 오버헤드가 발생하지 않음, HP(고성능)
- 단점 : 가상머신을 만드는 OS 한정(Host OS와 Guest OS가 같아야함. 도커는 그렇지도 않음)
VM 아키텍쳐 유형
hypervisor(VMM), 전가상화
-
virtualization layer on bare machine
- 호스트 os를 수정할 필요 없다
- noncritical 명령은 HW에 직접 수행
- critical은 control sensitive, behavior sensitive
- critical 명령을 hypervisor에서 emulate한다 <- runtime overhead

para-virtualization. 반가상화
- 게스트 os 를 수정해서 런타임 emulation 시간을 단축한다.(미리 compile)
- 가상화 오버헤드를 줄인다.
- 수정되지 않은 OS를 지원하기 위한 cost가 높다.
- 명령을 intercept하고 emulate하는 전가상화와 다르게 반가상화는 이를 컴파일 시간에 다룬다.

host-based virtualization
-
Host OS 위에 VMM올리고 Guest OS 올라감
- host os 상단의 가상화 계층
- 유연하지만 퍼포먼스 가장 낮다.
- 호스트 os와 gurest os 둘다 쓰임
- host os를 수정하지 않는다.
클라우드 플랫폼 아키텍처 죽지 말아야 함! high availability
노드, 상호연결망
- Data Center Interconnection Network
- Network Design Requirements
- 낮은 지연, 높은 대역폭, 적은 비용, message-passing interface(MPI), communication support, fault tolerance
- Fault Tolerance and Graceful Degradation
- 서버 FT
- 중복 서버 사이의 연산과 복제 데이터로 얻어짐
- 링크와 스위치의 FT
- 두 서버 노드 간 다수의 경로
- 소프트웨어 계층은 네트워크 failure를 알아야 하며, 클라우드 연산에 영향을 끼치지 않고 failure를 투명하게 handle해야 한다.
- Graceful Degradation. 서서히 나빠짐
- failure할 경우, 네트워크 구조는 서서히 degrade되야 한다.
- 계층적 상호연결 접근, no critial path(single point of failure), hot-swappable componets(전원 off하지 않음)
- 서버 FT
- 데이터 센터 Fat-Tree 상호연결
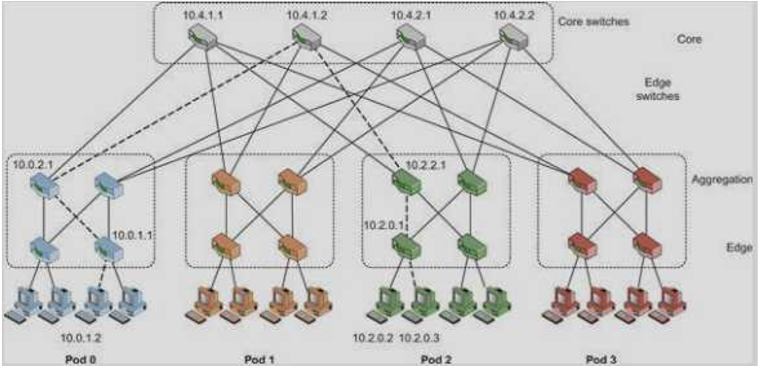
- switch link가 failure해도 hot-working path가 상실되지 않음 -> fault tolerant 하다
- Network Design Requirements
설계 이슈
- 데이터센터 관리 이슈
- 일반 유저들을 행복하게!
- 제한된 정보 흐름(서비스 유지와 높은 가용성을 위해)
- 다유저 관리성
- 데이터베이스 성장을 대비한 확장성
- 가상 인프라의 신뢰성
- 제공자와 유저 모두 낮은 비용
- 보안 강요와 데이터보호
- green IT. 전기를 좀만 써라
- 구조 설계 이슈
- 서비스 availability와 데이터 lock-in 문제
- 다수의 클라우드 제공자를 사용
- API 표준화
- 데이터 privacy와 보안 문제
- 전통적 : 버퍼 오버플로우, DOS공격, 스파이웨어, 맬웨어
- 클라우드 환경 : 하이퍼바이저 맬웨어, 게스트 호핑과 하이재킹 등
- 예상불가능한 성능과 병목현상
- 입출력장치 공유가 문제 - 효율적으로 가상화한다 인터럽트와 입출력 채널을
- 분산 스토리지와 널리퍼진 소프트웨어 버그
- 효율 분산 SANs
- 클라우드 확장성, 상호운용성, 표준화
- 소프트웨어 라이센싱과 평판(블랙리스트) 공유
- 서비스 availability와 데이터 lock-in 문제
클라우드의 가용성 및 보안
- Cloud Security Defense Strategies
- Basic Cloud Security
- 데이터센터의 시설 보안
- 생체인식, CCTV, 모션 디텍션
- 네트워크 보안
- 방화벽, IDS, 서드파티 취약점 평가
- 플랫폼 보안
- SSL(secure socket manager), 엄격한 패스워드 정책, 시스템 신뢰 인증
- 데이터센터의 시설 보안
- 특별한 보안 보호를 요구하는 클라우드 컴포넌트들
- 서버 : worms, viruse, malware 같은 악의적인 소프트웨어 공격으로부터
- 하이퍼바이저나 VMM : 취약성을 착취하는 소프트웨어 기반의 공격으로부터
- VM과 VMM : 서비스 붕괴와 Dos 공격으로부터
- VM에서의 보안 문제
- 예민 데이터나 암호를 훔치는 수동적 공격
- 커널 데이터 구조를 조작하는 능동적 공격
- 방어 기술
- NIDS, HIDS, program shepherding(코드 실행을 방어), 단단해진 OS환경, 고립된 실행(sandboxing)
- 클라우드 방어 방법
- VM의 failure는 다른 VM에게 전파되지 않음
- 한 VM에 대한 보안 공격은 다른 VM에 영향을 주지 않고 격리된다.
- 하이퍼바이저는 완벽하게 게스트OS를 고립시켜야 한다
- PKI 서비스는 데이터 센터 평판 시스템과 함께 논의되어야 한다.
- 가상화를 이용한 보안
- VM은 HA를 가능하게 하며 빠른 재앙 복구가 가능
- VM의 live 이주는 제안된다 많은 연구자들로부터. 분산 IDSes를 지음으로써
- Basic Cloud Security
SOA service oriented architecture
공개되거나 발견 가능한 인터페이스를 통해 신규 또는 레거시 애플리케이션의 서비스를 이용하는 소프트웨어 시스템을 설계하는 방법
- 서비스 상호 운용성을 확장 가능하고 효과적으로 만든다.
- 느슨한 결합, 게시된 인터페이스 및 표준 통신 모델과 같은 아키텍처 스타일
REST, Web 서비스
- REST (REpresentational State Transfer)
- A software Architecture Style for Ds, WWW
- 아마존, 야후와 같은 기업과 소셜 네트워크 사이에서 인기를 얻었다. 단순성과 클라이언트의 소비 및 배포 용이성 때문에
- 라지 스케일 분산 시스템을 위한 디자인과 구조 스타일
- 표준이 아님.
- 4 디자인 원칙
- URI를 통한 자원 식별
- 서비스 검색을 용이하게 할뿐만 아니라 구성 요소 간의 상호 작용과 관련된 자원에 대한 전역 주소 지정 공간을 제공합니다
- 균일하고 제한된 인터페이스
- 리소스는 4 개의 CRUD (생성, 읽기, 업데이트, 삭제) 동사 또는 작업의 고정 된 집합을 사용하여 조작됩니다 : PUT, GET, POST, DELETE
- POST는 리소스에게 새로운 상태를 전달합니다.
- self-Descriptive message
- 리소스는 다양한 표현 형식 (HTML, XML, MIME, 일반 텍스트, PDF, JPEC, JSON 등)으로 액세스 할 수 있도록 표현과 분리됩니다.
- 자원에 대한 메타 데이터는 사용 가능하며 캐시 제어, 전송 오류 감지, 인증 또는 권한 부여 및 액세스 제어와 같은 다양한 목적으로 사용될 수 있습니다.
- Stateless Interaction
- 메세지의 의미는 대화의 상태에 의존하지 않는다.
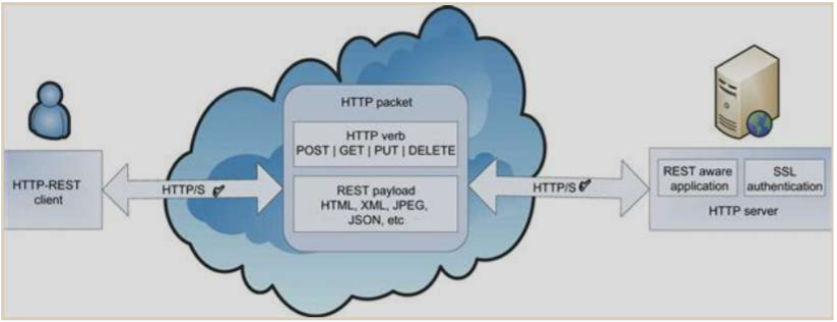
- URI를 통한 자원 식별
- RESTful Web Service
- 단순성, 가벼운 환경, HTTP로 통합
- URI와 하이퍼링크의 도움으로 웹 자원을 중앙형 저장소에 대한 등록에 기반한 접근 없이 발견할 수 있다
- RESTful 웹 서비스의 구성은 매시업과 같은 복합 웹 2.0 애플리케이션의 주요 초점이었다.
- A software Architecture Style for Ds, WWW
- Web Services
- SOA 구현의 인스턴스
- SImple Object Access Protocol(SOAP), XML-RPC의 확장
- XML문서의 전송. HTTP, SMTP, FTP 등을 통한
- SOAP 메시지 루트 요소, 헤더와 바디의 봉투
- Web services Description Language (WSDL)
- 인터페이스를 설명, 웹 서비스가 지원하는 연산들의 집합
- Universal Description, Discovery, and Integration(UDDI)
- SImple Object Access Protocol(SOAP), XML-RPC의 확장
- WS-I Protocol stack
- RESTful 웹 서비스와 다르다. QoS와 계약 속성을 커버하지 않는다.
- SOAP-based 웹 서비스는 보장한다 특정 레벨의 퀄리티를. 메세지 통신에서. 신뢰성, 전송 정책 뿐만 아니라. Ws-보안, WS-동의, WS-의존메시징, WS-전송, WE-동등과 같은.
- 웹 서비스를 위한 비즈니스 프로세스 실행 언어
- OASIS에서 권장하는 웹 서비스 간의 상호 작용을 지정하는 표준 실행 가능 언어
- 비즈니스 목표를 완료하기 위한 실행 단계인 대규모의 상태 저장 서비스
- 보다 복잡한 웹 서비스와 워크 플로우를 만들기 위해 함께 구성된 웹 서비스

- SOA 구현의 인스턴스
병렬 프로그래밍 Hadoop
패러다임
-
분산 컴퓨팅 시스템과 병렬 컴퓨팅
- 분산 컴퓨팅 시스템
- 네트워크로 연결된 컴퓨터적 엔진의 집합. running a job or application 하는 공통의 목적을 얻기 위해.
- 병렬 컴퓨팅
- 한 개 이상의 컴퓨터 엔진을 동시사용하여 job을 처리한다.
- 분산 또는 비분산 컴퓨팅 시스템의 사용(멀티프로세서 플랫폼과 같은)
- 분산 컴퓨팅 시스템
-
병렬과 분산 프로그래밍
- 분산 컴퓨팅 시스템에서 병렬 프로그램 실행
- 유저의 관점 : 애플리케이션 리스폰스 타임의 감소
- 분산 컴퓨팅 시스템의 관점 : throughput과 자원 사용성의 증가
- 분산 컴퓨팅 시스템에서 병렬 프로그램 실행
-
병렬 & 분산 프로그래밍 패러다임
-
병렬 프로그램 실행의 이슈
-
Partitioning
-
Computation partitioning
- 주어진 job이나 프로그램을 작은 task로 나눈다
- 동시에 수행 될 수있는 작업 또는 프로그램의 부분 식별
-
Data partitioning
- 입력이나 중간 데이터를 작은 조각으로 나눔
-
-
Mapping
- 데이터나 프로그램의 작은 부분을 기본 자원에 할당
-
동기화
- 작업자 간 동기와 coordination(동등하게 하다)이 필요하다. 경쟁 조건의 예방과 적절히 데이터 의존성을 관리하기 위해
-
통신
- 거의 overhead. 병렬 처리를 하기 때문에 생긴다.
-
Scheduling
-
-
병렬 컴퓨팅과 프로그래밍 패러다임
- 프로그래밍 패러다임의 동기
- 프로그래머 생산성 향상
- 프로그램의 시간 감소
- 기본 자원의 효율적인 활용
- 시스템 처리량의 증가
- 높은 수준의 추상화 지원
- 프로그래밍 패러다임의 동기
-
Hadoop : MapReduce
-
MapReduce
- 큰 데이터셋에 대한 병렬과 분산 컴퓨팅을 지원하는 소프트웨어 프레임워크.
- 데이터 흐름의 추상화. 두 기능으로 형성된 두 인터페이스 : Map & Reduce
- 논리적 데이터 흐름 Map부터 Reduce 함수까지.

- ‘value’는 실제 데이터, ‘key’는 데이터 흐름을 통제하기 위해 쓰인다.
- Map과 Reduce 함수는 유저에 의해 오버라이드될 수 있다. 특정 목적를 달성하기 위한
-
MapReduce Logical data flow
-
input data to the Map function
- (key, value) 쌍 형식에서, key는 입력 파일의 라인 오프셋이고, value는 line의 내용이다.
-
output data from the Map function
- 수(zero, one, or more) 중간 (key, value) pairs
- 데이터는 정렬된다. group process를 simplify하기 위해
-
input data to the Reduce function
-
단어카운트의 합산
- 하나의 중간 키와 관련된 중간값 그룹. (key. [set of values])
-
-
output data from the Reduce function
- Reduce function은 각 그룹을 처리하고 (key, value) 집합을 출력한다.
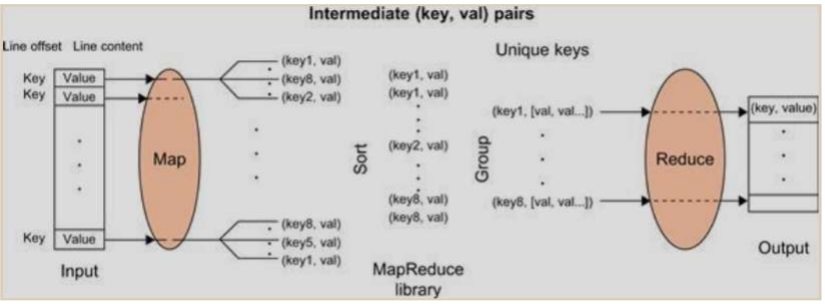
Map funciton이 시간이 많이 걸린다. <- 여러 노드를 사용. Reduce는 조금 사용
-
a word count problem
-

-
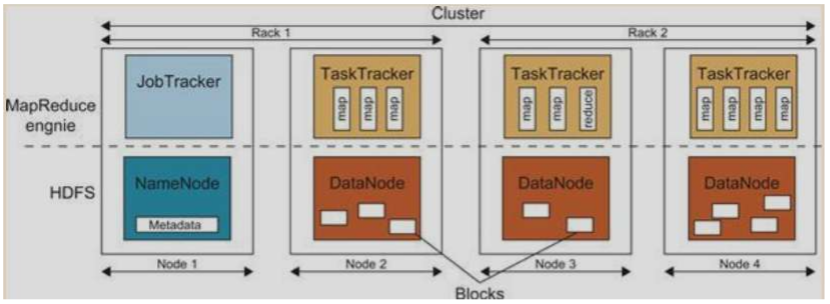
HDFS : Hadoop Distributed File System
- Hadoop
- MapReduce의 실행 오픈 소스
- HDFS를 기본 계층으로 사용.
- 하둡 코어는 두 기본 계층으로 분리된다
- MapReduce 엔진
- HDFS
- HDFS
- GFS에서 영향을 받음. 파일을 조직하고 DCS에 데이터를 저장한다
- master / slave 구조는 single NameNode를 마스터로. 여러 DataNodes를 slave로 포함한다
- 파일 저장
- 파일을 고정 사이즈 블록으로 나누고 worker(DataNodes)에게 저장한다.
- 블록에서 DataNode로의 매핑은 NameNode에 의해 결정된다.
- namespace
- 메타데이터를 유지하는 영역
- Features
- 일반 목적 아님(성능, 확장성, 동시성 제어, falut tolerance, 보안 같은)
- Falut Tolerance
- 파일 블록 복제
- 복제품 배치(원래 데이터가 저장되는 동일한 노드 또는 동일한/다른 랙의 다른 노드)
- 각 DataNode에서 주기적 심장박동
- 큰 데이터셋(파일)으로의 높은 처리량 접근
- 배치 처리를 위해 설계됨. 상호 처리보다는
- 데이터의 빠른 흐름 읽기. 파일마다 요구되는 감소된 양의 메타데이터 저장소.
- operation
- 파일 읽기
- ‘open’은 NameNode에게 file block의 위치를 얻도록 요청한다.
- NameNode는 DataNode의 집합의 주소를 반환한다.
- ‘read’는 적절한 블록을 포함하는 가까운 DataNode에 연결한다
- 파일 쓰기
- ‘create’는 NameNode에게 파일 시스템 namespace에 새 파일을 생성하라고 요청한다.
- 파일의 첫 블록은 내부 데이터 큐에 작성되었다.
- ‘Data Streamer’는 NameNode에게 요청을 보낸다. 적절한 DataNode를 얻도록. 복제품 저장과 DataNode로의 쓰기를 감독하기 위한.
- 파일 읽기
- Hadoop Library from Apache
- MapReduce engine
- MapReduce job의 데이터 흐름과 제어 흐름을 관리
- master/slave 구조(single JobTracker가 master, 여러 TaskTrackeras는 slave workers)
- MapReduce engine
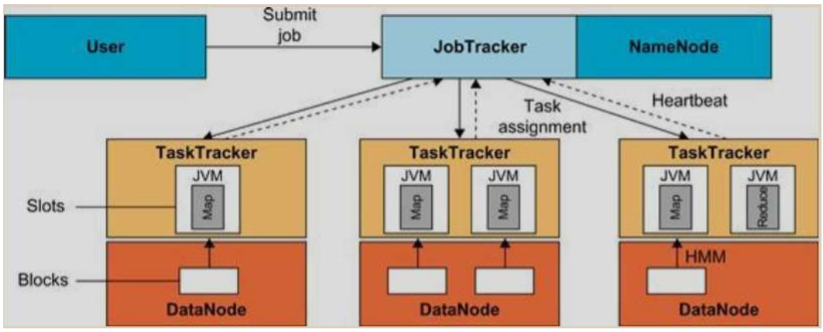
- Running a Job in Hadoop
- 유저 프로그램 한 runJob 함수를 호출
- job submission
- 유저 노드는 JobTracker로부터 새로운 job ID 를 요청한다, 자원을 복제, job을 submit한다.
- task assignment
- JobTracker는 각각의 computed input split마다 Map task를 만든다. 그리고 Map task를 TaskTracker의 실행 슬롯에 할당한다
- JobTracker는 또한 Reduce 태스크를 생성하고 TaskTracker에 할당한다
- task execution
- 태스크를 실행하기 위한 제어 흐름(Map or Reduce)은 TaskTracker 안에서 시작하고 job JAR 파일을 file system으로 복사한다
- job JAR 파일 안에 있는 명령은 JVM 실행 후에 수행된다.
- task running check
Grid, CPS
Grid
- 이질적인 컴퓨터가 자원의 큰 컬렉션을 만든다.
- 다른 기관의 자원들이 통합되어 많은 유저들에 의해 공유된다.
- CPU Scavenging : 사용되지 않는 자원을 이용
- Grid Information Service : 유용성과 공개 자원의 명세를 제공
- Open Grid Services Architecture(OGSA)
- 2개의 큰 소프트웨어 기술로 구성
- Globus Toolkit이 널리 채택된다. 그리드 기술 솔루션으로
- 웹 서비스 2.0은 인기있는 표준 프레임워크다
- Service Oriented
- 2개의 큰 소프트웨어 기술로 구성
- Grid Data Access Models
- Monadic 중심
- Hierarchy 계층
- Federation 협의
- Hybrid 계층 + 협의
CPS : Cyber Physical System
- 독립형 장치 대신 물리적 입력 및 출력과 상호작용하는 요소 네트워크
- CPS의 잠재력
- 분쟁에 개입
- 정확성
- 위험하거나 접근불가한 환경에 작동
- 조직화
- 효율성
- 인력의 증가
- 아키텍처
- Smart Connection level
- Data to information Conversion Level
- Cyber level
- Cognition level
- Configuration level
댓글남기기