CSAPP(6) - The Memory Hierarchy
업데이트:
1. Storage Technologies
1.1. Random Access Memory
- 크게 static과 dynamic으로 분류
- SRAM
- DRAM보다 빠르고 비쌈
- 캐시 메모리로 쓰임
- 몇십 메가바이트
- DRAM
- 메인 메모리
- 그래픽 시스템의 프레임 버퍼
- 몇천 메가바이트
- SRAM
Static RAM
- bi-stable한 특성을 갖고 있음
- 전원이 들어오는 한 값을 무한히 유지
- disturb 하더라도 안정된 값으로 돌아옴
Dynamic RAM
- 각 비트를 커패시터의 충전으로 저장
- disturb에 매우 예민
- 10~100 ms 기간으로 충전이 유실됨
- 메모리 시스템은 주기적으로 메모리의 모든 비트를 refresh
- 몇몇 시스템은 에러 수정 코드를 사용
Conventional DRAMs
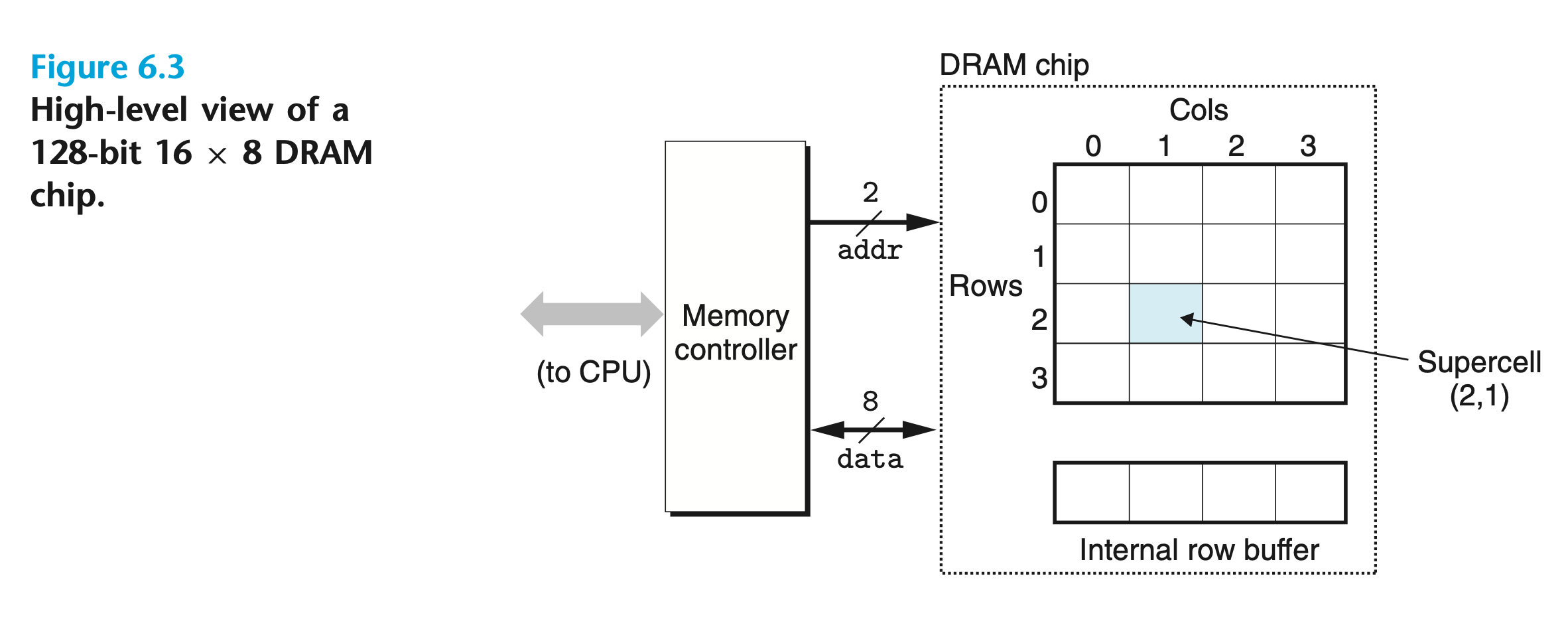
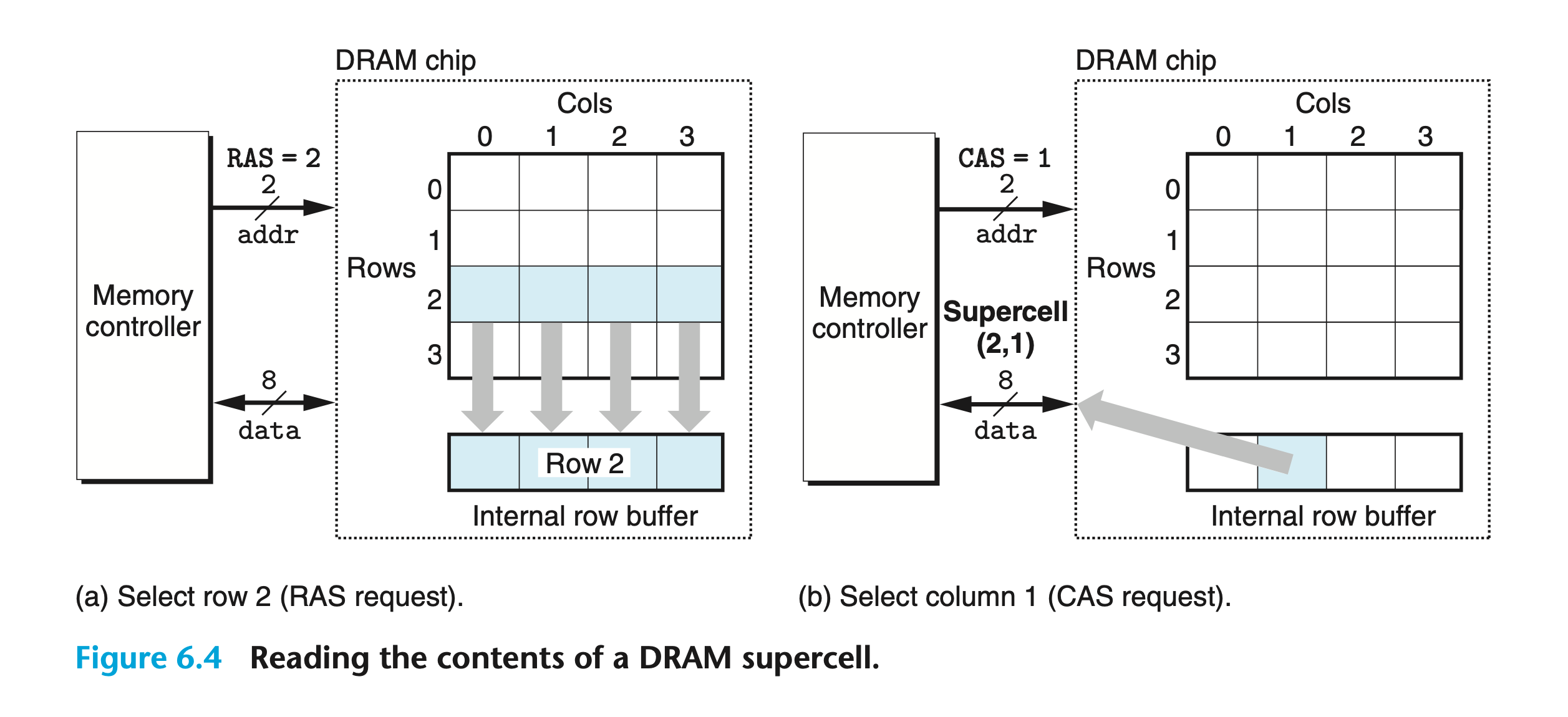
addr라는 2비트 좌표값을 통해 supercell을 읽는다. supercell은 8비트 데이터 크기.- 2차원 배열 설계는 선형 배열 설계보다 더 적은
addr비트 수를 사용할 수 있다. 다만, 두번의 구분된 단계를 통해 접근하기에 접근 시간이 오래 걸린다.
Memory Modules

- 64MB 를 저장
- DRAM은 총 8M개 supercell
- 한 supercell은 8bit
- 메모리 컨트롤러는
- 가져올 word에 해당하는 메모리 주소 A를 superset 좌표 (i,j)로 변환
- 각 DRAM에 i, j를 브로드캐스트
- 각 DRAM에서 8비트씩. 총 64bit를 받아
- CPU에게 word 전달
Enhanced DRAMs
여러 가지 있다. i7은 DDR3 SDRAM만 지원한다.
- Double Data-Rate Synchronous DRAM 의 8bit prefetch buffer 타입
Nonvolatile Memory
ROMs
- 몇 번이나 programmable 하냐에 따라 세부 유형이 나뉨
- Flash Memory 또한 ROM 기반
- 현대에는 flash 기반의 디스크인 SSD로 발전됨
- ROM에 저장되는 프로그램이 바로 firmware.
- BIOS(basic input/output system), 그래픽카드, 디스크 드라이브 컨트롤러 등은 CPU로부터의 입출력 요청을 변환하기 위해 펌웨어를 사용한다.
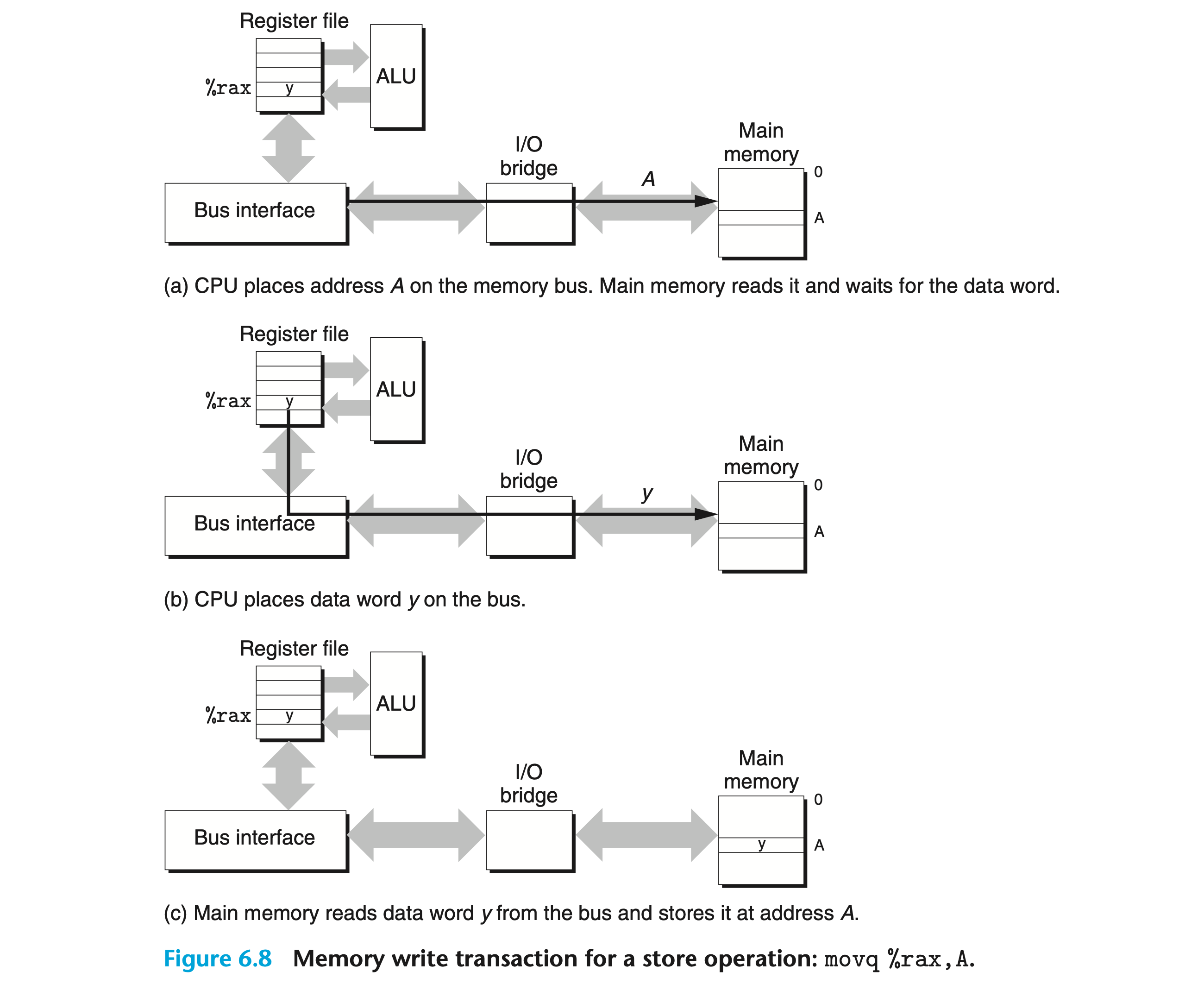
Accessing Main Memory
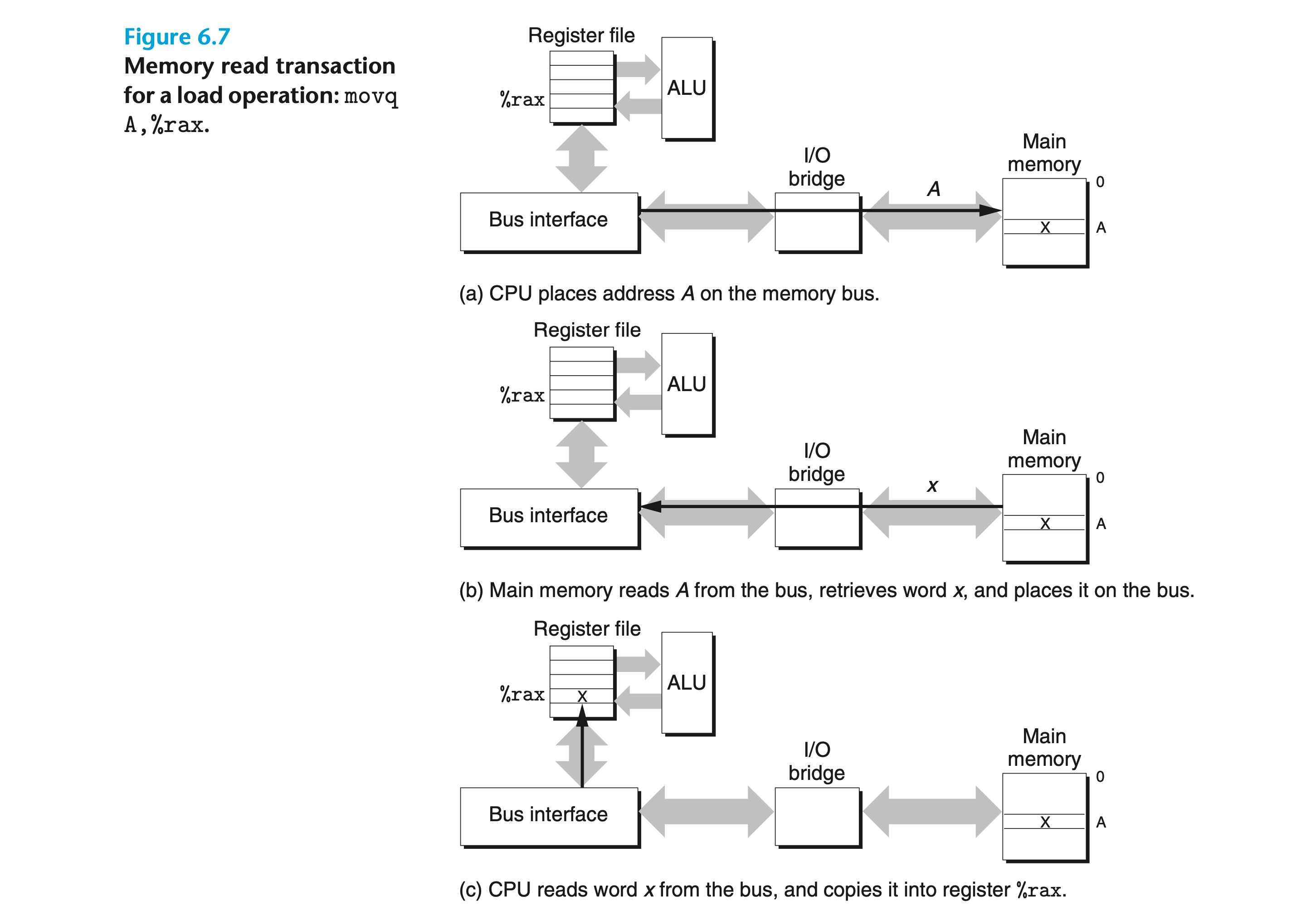
- 데이터는 buses를 통해 CPU와 DRAM 메인 메모리 사이를 왔다갔다한다.
- 각 전달은 bus transaction 이라고 하는 단계의 연속으로 구성된다.
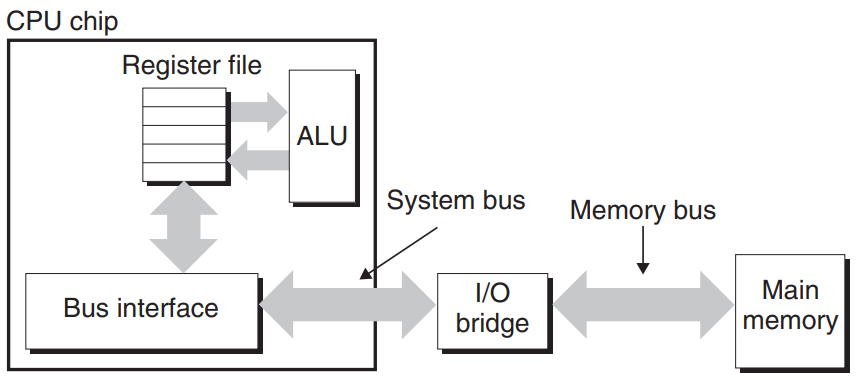
- I/O bridge 는
- 메모리 컨트롤러를 포함.
- system bus의 전기 신호를 memory bus 의 전기 신호로 변환
- 디스크나 그래픽 카드와 같은 입출력 장치를 시스템, 메모리 버스와 연결
1.2. Disk Storage
디스크는 많은 양의 데이터를 저장하지만, RAM보다 읽기 속도가 현저히 느리다.
Disk Geometry

Disk Capacity
- 일반적으로 섹터당 512byte를 저장한다.
- $capacity = \frac{\sharp bytes}{sector} * \frac{average \sharp sectors}{track} * \frac{\sharp tracks}{surface} * \frac{\sharp surface}{platter} * \frac{\sharp platters}{disk}$
Disk Operation
- 섹터의 접근 시간은 3가지로 나뉜다.
- Seek time : 암이 헤드를 목적 섹터로 움직이는 시간
- Rotational latency : 헤드가 목적 섹터에 도달하도록 회전을 대기하는 시간
- Transfer time : 한 섹터에서 데이터를 전송하는 시간. 위 두개보다는 많이 짧다
Local Disk Blocks
- 현대 디스크는 B 섹터 크기의 logical blocks 시퀀스라는 인터페이스를 제공한다.
- disk controller는 물리적인 디스크와 logical block 을 매핑한다.
- OS는 disk controller에게 특정 block number 읽기 요청, 디스크 컨트롤러는 하드웨어에서 데이터를 읽어서 컨트롤러의 작은 메모리 버퍼에 모은다. 이후 메인 메모리에 복사한다.
Connecting I/O Devices
- I/O장치는 I/O bus를 통해서 CPU와 메인 메모리에 연결된다.
- I/O버스는 CPU와 독립적으로 설계되었다.
- 다양한 서드파티 I/O장치를 수용한다.

Accessing Disks
- Memory Mapped I/O시스템에서, 주소 공간의 일부는 I/O장치와 통신하는 것으로 예약된다. 이걸 I/O port라 한다.
- CPU가 disk sector를 읽는 과정
- CPU는 3가지 저장 명령을 port 주소에 실행함으로써 초기화
- 디스크의 읽기를 초기화하는 명령
- 읽을 logical block number를 가리키는 명령
- 데이터가 저장될 메인 메모리 주소를 가리키는 명령
- 요청 이후, CPU는 다른 일을 함. 비동기
- disk controller는 섹터의 데이터를 읽어서 메인 메모리로 직접 전송함(Direct Memory Access). CPU 간섭 없음
- DMA 전송이 끝나면, 컨트롤러는 CPU에게 인터럽트 신호를 보냄
- CPU는 하던 일을 멈추고 OS 루틴으로 점프. 루틴은 I/O가 끝났음을 기록하고, 중단 지점으로 제어를 반환.
- CPU는 3가지 저장 명령을 port 주소에 실행함으로써 초기화
1.3. Solid State Disks
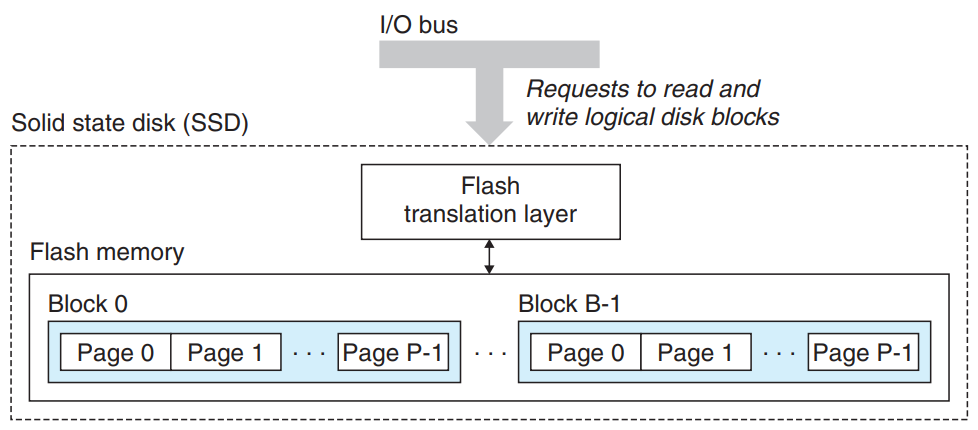
- 플래시 메모리 기반의 저장소
- SSD package는 I/O bus 표준 디스크 슬롯에 장착된다.
- SSD package는 한 개 이상의 플래시 메모리 칩으로 구성.
- Flash Translation layer는 하드웨어/펌웨어 장치로 disk controller와 동일한 역할
- 회전 디스크보다 장점 : 빠른 랜덤 액세스. 적은 파워. 더 엄격
- 회전 디스크보다 단점 : flask기반이라 마모 가능성. 비쌈
1.4. Storage Technology Trends
- 빠를수록 비싸다.
- 밀도를 높이는 것이 접근 시간을 감소시키는 것보다 훨씬 쉽다.
- 현대 컴퓨터는 SRAM 기반의 캐시를 주로 사용한다.
2. Locality
지역성 원칙이란. 최근에 참조한 데이터나 그 주변 데이터를 주로 참조하는 경향을 말한다.
- 공간 지역성 : 메모리 공간이 한번 참조되면 근처 메모리 공간을 다시 참조하는 경향
- 시간 지역성 : 한번 참조된 메모리 공간은 금방 다시 참조되는 경향
- 지역성이 좋으면 속도가 빠르다
- 하드웨어 수준에서 캐시 메모리로 메인 메모리 접근을 빠르게
- OS 수준에서 메인 메모리를 캐시로 사용하여 최근에 참조된 가상 주소 공간 청크 참조를 빠르게, 최근에 사용한 디스크 블락 참조를 빠르게.
- 어플리케이션 수준에서는 웹 서버에서 최근에 참조된 문서를 프론트엔드 디스크에 캐시. 브라우저에서는 최근에 참조한 문서를 로컬 디스크에 캐시.
2.1. Locality of References to Program Data
- stride-1 reference pattern
- 벡터의 각 요소를 순차적으로 접근하는 패턴
- == sequential reference pattern
- 높은 공간 지역성
- stride-k reference pattern
- 벡터의 연속된 k번째 요소를 방문하는 패턴
- k가 증가할수록 공간 지역성 감소
- 다차원 배열에서 행 기반으로 접근하는 것이 열 기반보다 높은 공간 지역성
- C배열은 메모리의 row기반으로 배치된다.
2.2. Locality of Instruction Fetches
프로그램 명령 또한 메모리에 있고 CPU가 가져와야 하기에, 명령어를 가져오는 지역성도 평가할 수 있다.
- for 루프는 여러 번 실행되기에 좋은 시간 지역성.
- for 루프내 명령은 순차적인 순서로 실행되기에 좋은 공간 지역성.
2.3. Summary of Locality
- 반복하여 같은 변수를 참조하는 것은 좋은 시간 지역성
- stride-k 접근 패턴에서 k가 작을수록 공간 지역성 증가
- 루프는 좋은 시간/공간 지역성. 루프 바디가 작을 수록, 루프 순회가 많을수록 지역성은 증가한다.
3. The Memory Hierarchy
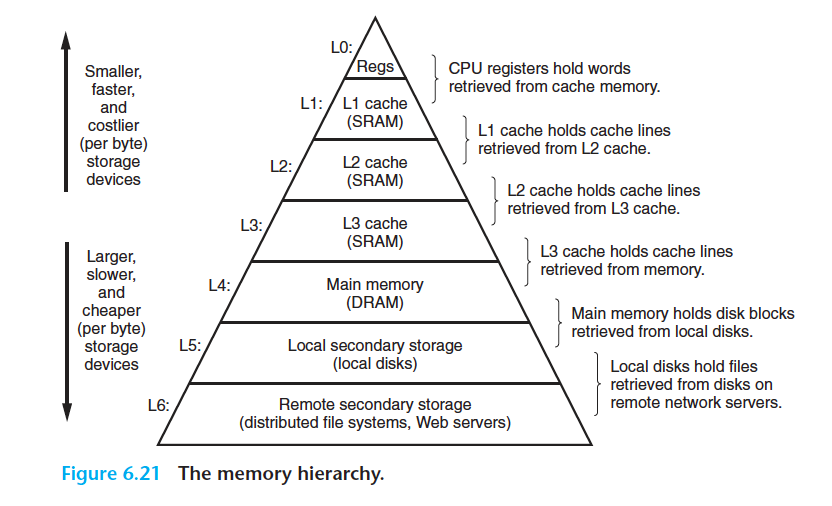
3.1. Caching in the Memory Hierarchy
메모리 계층의 중점 아이디어는 k레벨의 스토리지가 k+1 레벨의 스토리지를 캐시하는 것이다.
- CPU 레지스터는 가장 작은 캐시라고 볼 수 있다.
데이터는 블락 크기로 전송된다.
- 연속된 데이터 묶음을 block이라 한다.
- 블락 크기는 인접한 레벨에서는 동일하다. 다만, 다른 쌍의 레벨에서는 다른 블락 크기를 가진다.
- 낮은 계층일수록 긴 접근 시간을 가지기 때문에, 큰 블락 크기를 통해 접근 시간을 완화한다.
k레벨에서 k+1레벨의 데이터를 접근하려 한다. 데이터가 k레벨에 캐시되어 있으면 cache hit라 하고, 없다면 cache miss 라 한다.
캐시 미스로 k레벨에 존재하는 블락을 덮어쓰는 것을 evict라 한다. 방출 대상 블락을 victim block이라 한다.
- 어떤 블락이 희생될지는 캐시의 replacement policy를 따른다.
캐시 미스의 종류
- cold cache로 인한 미스 : compulsory misses / cold misses
- 캐시가 비어있는 것을 cold cache라 한다.
- 반복된 접근으로 warm up 된 이후에는 발생하지 않는다.
- conflict miss
- 하드웨어는 비싸기에 복잡한 정책을 가지지 않는다. 따라서 그냥 인접한 블락을 캐시한다.
- 때문에 반복된 참조에도 불구하고, 멀리 떨어진 블락은 계속 미스가 난다.
캐시 관리
- L1,L2,L3 캐시는 하드웨어 로직에 의해 관리된다.
- 가상 메모리 시스템에서 DRAM 메인 메모리는 disk의 데이터 블락을 캐시한다.
- OS와 CPU의 주소 변환 하드웨어에 의해 관리된다.
- 분산 파일 시스템에서는 로컬 머신의 파일 클라이언트에 의해 관리된다.
3.2. Summary of Memory Hierarchy Concepts
지역성과 캐시
- 시간 지역성 때문에, 캐시 히트가 연속적으로 발생하여 성능은 빨라진다.
- 공간 지역성 때문에, 인접한 후속 참조는 동일한 블락에 캐시되었을 확률이 높다.

4. Cache Memories
4.5. Issues with Writes
캐시 읽기 연산은 직관적이다. 캐시 히트시 즉시 반환하면 되고 캐시 미스 시에는 다음 레벨의 메모리 계층에서 워드를 가져와 캐시에 저장하면 된다.
쓰기는 복잡하다. 캐시된 데이터를 write하게 되면 다음 레벨의 메모리 계층에 있는 데이터도 업데이트해야 한다.
- 단순한 방법으로 write-through가 있다. 즉시 다음 계층에 쓴다.
- 단점 : 매 쓰기 시마다 버스에 트래픽이 생긴다.
- 장점 : 구현이 쉽다. 읽기 미스가 메모리 쓰기를 하지 않기 때문에 비용이 적다.
- write-back은 쓰기 연산을 미룬다. 데이터가 캐시에서 방출될 때, 다음 레벨 메모리 계층에 쓴다.
- 장점 : 지역성 때문에 버스 트래픽을 많이 줄일 수 있다.
- 전송의 수를 줄이는 것은 아래 계층으로 갈수록 중요해진다.
- 단점 : 캐시는 추가적인 dirty bit를 유지해야 한다. dirty bit는 캐시가 수정되었는지를 표시한다.
- 장점 : 지역성 때문에 버스 트래픽을 많이 줄일 수 있다.
write miss 의 경우는 어떻게 할까
- write-allocate는 미스 시에 캐시 메모리로 데이터를 불러와서 캐시 블락을 업데이트한다.
- 지역성을 활용하는 방식
- 단점 : 매 미스마다 캐시로 불러와야 함.
- no-write-allocate는 캐시를 bypass하고 다음 계층에 직접 쓴다.
일반적으로 write-through는 no-write-allocate. write-back은 write-allocate이다.
write-back, write-allocate 캐시 모델을 사용하는 것을 권장한다.
- virtual memory 시스템도 이렇게 되어 있고
- 최신 트렌드이기도 하며
- 시공간 지역성을 최대로 활용하는 방식이다.
4.6. Anatomy of a Real Cache Hierarchy
최신 프로세서는 별도의 i-cache(명령어 캐시), d-cache(데이터 캐시)를 가진다.
- 최신 프로세서는 명령어 워드와 데이터 워드를 동시에 읽을 수 있기 때문.
- i-cache는 읽기 전용이기 때문에 둘을 각각 최적화할 수 있음.
4.7. Performance Impact of Cache Parameters
캐시 크기가 클수록 히트율은 높다. 하지만 큰 메모리가 빠르기는 어렵다. 그래서! L1캐시가 L2보다, L2보다 L3보다 작게 설계된 것이다.
5. Writing Cache-Friendly Code
코드는 캐시 친화적이어야 한다.
- 일반적인 상황에서 빠르게 동작하게 하라.
- 자주 호출되는 함수에 집중해라.
- 캐시 미스를 최소화하라.
- 지역 변수를 반복 참조하라. 컴파일러는 레지스터에 변수를 캐시한다(시간지역성)
- stride-1 참조 패턴은 공간 지역성이 좋다.
- C는 row기반으로 배열을 저장하기 때문에 동일 row를 순차적으로 접근하는게 좋다.
출처
- https://csapp.cs.cmu.edu/
- 책 “Computer Systems : A Programmer’s Perspective”
댓글남기기