분산컴퓨팅(2)-HDFS 
업데이트:
숭실대학교 박영택교수님의 “빅데이터분산컴퓨팅” 강의를 참고했습니다.
HDFS
- HDFS는 Java로 작성된 파일 시스템
- 구글의 GFS 기반
- 기존 파일 시스템의 상위에서 동작
- ext3, ext4, xfs
HDFS의 파일 저장 방식
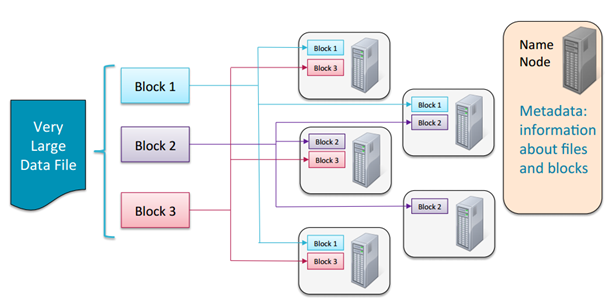
- File은 block 단위로 분할
- 각 block은 기본적으로 64MB 또는 128MB 크기
- 데이터가 로드될 때 여러 machine에 분산되어 저장됨
- 같은 file의 다른 block들은 서로 다른 machine에 저장됨
- 효율적인 MapReduce 처리가 가능
- Block들은 여러 machine에 복제되어
DataNode에 저장됨- 기본 replication은 3개
- 각 block은 서로 다른 3개의 replication이 저장되어 있다는 것을 의미
- 기본 replication은 3개
-
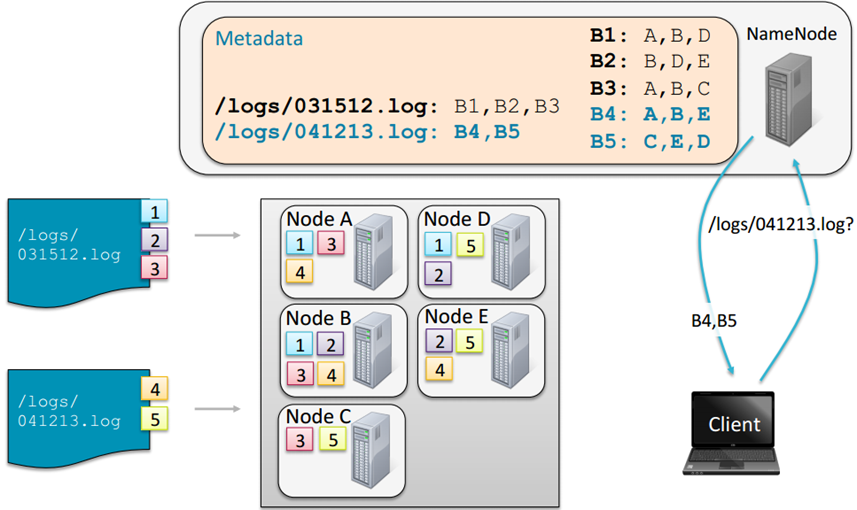
NameNode로 불리는 master node는 어떤 block들이 file을 구성하고 있고, 어느 위치에 저장되어 있는지에 대한 정보를 metadata로 관리
HDFS
-
File이 block으로 분할될 때, file이 block크기보다 작은 경우에는 block 전체를 사용하지 않음
-
Block들은 Hadoop Configuration에 설정된 디렉토리를 통해 저장됨
-
NameNode의 metadata를 사용하지 않으면, HDFS에 접근 불가
-
클라이언트 애플리케이션이 file에 접근하는 경우
- NameNode와 통신하여 file을 구성하고 있는 block들의 정보와 DataNode의 block의 위치 정보를 제공받음
- 이후 데이터를 읽기 위해 DataNode와 직접 통신
- NameNode는 bottleneck이 되지 않음
HDFS 접근 방법
- Shell 커맨드 라인을 사용 :
$hadoop fs - Java API
- Ecosystem
- Flume
- network source로부터 데이터 수집
- Sqoop
- HDFS와 RDBMS 사이의 데이터 전송
- Hue
- Web기반의 interactive UI로 browse, upload, download, file view 등이 가능
- Flume
Storing and Retrieving Files
HDFS NameNode Availability
-
NameNodedeamon은 반드시 항상 실행되고 있어야 함- 중단시 클러스터는 접근 불가능
- High Availability mode
- 2개의 NameNode : Active와 Standby
- Classic mode
- 1개의 NameNode
- 또 다른 ‘helper’ node는 SecondaryNameNode
- backup 목적이 아니며, 장애 발생 시 NameNode를 대신할 수 없음
- NameNode를 복구할 수 있는 정보를 제공
Hadoop Server roles
Hadoop의 구성 요소
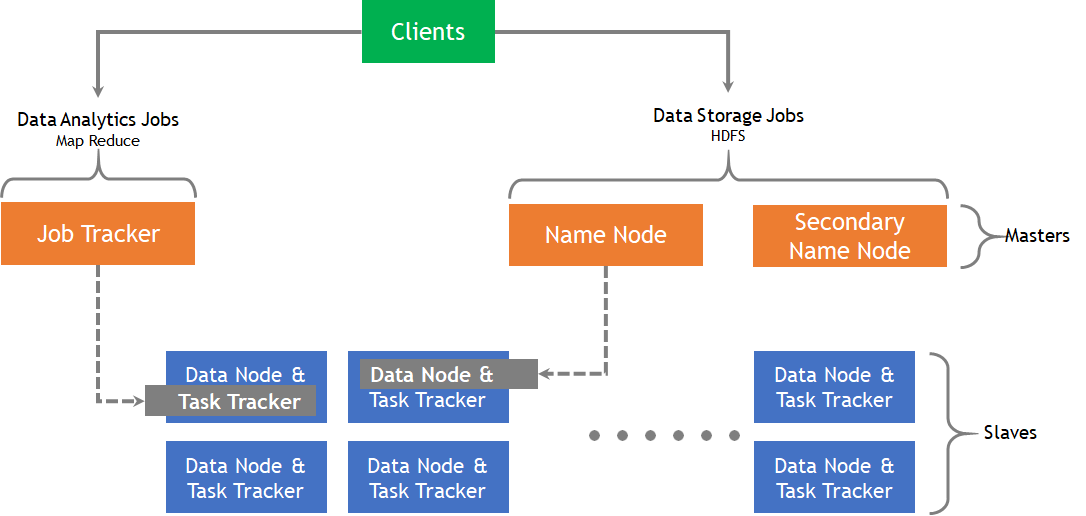
- Client
- NameNode를 통해 정보를 받고 이후 직접적으로 DataNode와 통신한다
- NameNode
- 물리적으로 master node역할(Job Tracker, NameNode)을 하는 노드로서 DataNode에 대한 정보와 실행을 할 Task에 대한 관리를 담당
- DataNode
- 물리적으로 Slave node역할(DataNode, Task Tracker)을 하는 노드로서, 실제로 데이터를 분산되어 가지고 있으며 Client에서 요청이 오면 데이터를 전달하고 담당 task를 수행하는 역할
- 두 가지 관점
- Data Analytics 관점
- Job Tracker : 노드에 Task를 할당하는 역할과 모든 Task를 모니터링 하고 실패할 경우 Task를 재실행하는 역할
- Task Tracker : Task는 Map Task와 Reduce Task로 나눌 수 있으며 Task가 위치한 HDFS의 데이터를 사용하여 MapReduce 수행
- Data Storage 관점
- NameNode : HDFS의 파일 및 디렉토리에 대한 metadata를 유지, 클라이언트로부터 데이터 위치 요청이 오면 전달, 장비 손상 시 Secondary Node로 대체
- DataNode : 데이터를 HDFS의 Block 단위로 구성, Falut Recovery를 위해 default로 3 copy를 유지, Heartbeat 통하여 지속적으로 파일 위치 전달
- Data Analytics 관점
댓글남기기