분산컴퓨팅(3)-MapReduce 
업데이트:
숭실대학교 박영택교수님의 “빅데이터분산컴퓨팅” 강의를 참고했습니다.
MapReduce
- 여러 노드에 태스크를 분배하는 방법
- 각 노드 프로세스 데이터는 해당 노드에 저장(가능한 경우)
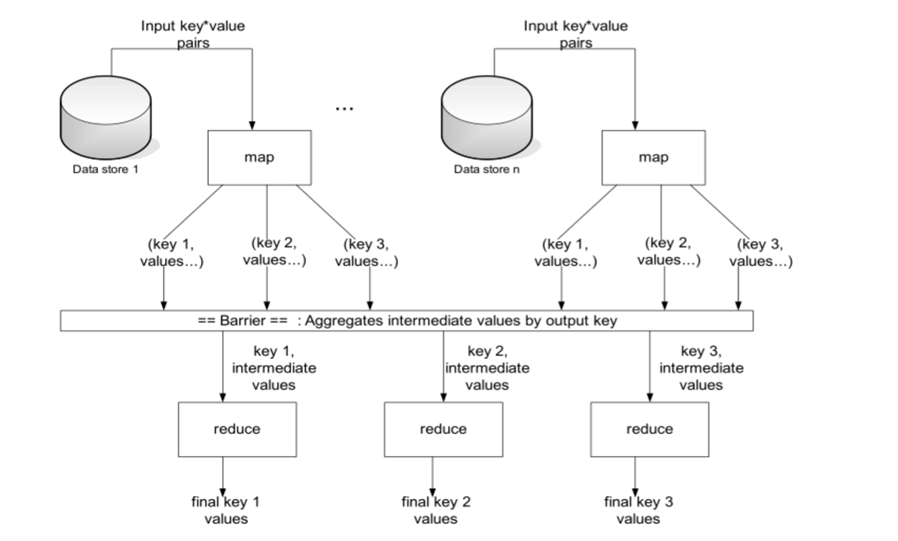
- 두 단계로 구성
- Map - Reduce
- Map 과 Reduce 사이에는 shuffle과 sort라는 스테이지가 있음
- 각 Map task는 전체 데이터 셋에 대해서 별개의 부분에 대한 작업을 수행
- 기본적으로 하나의 HDFS block을 대상으로 수행
- 모든 Map task가 종료되면, MapReduce 시스템은 intermediate 데이터를 Reduce phase를 수행할 노드로 분산하여 전송
JobTracker
- 맵리듀스 Job들은 JobTracker라는 소프트웨어 데몬에 의해 제어됨
- JobTracker는 ‘Master Node’에 있음
- 클라이언트는 맵리듀스 Job을 Job Tracker에게 보낸다
- JobTracker는 클러스터의 다른 노드들에게 맵과 리듀스 Task를 할당한다
- 이 노드들은 TaskTracker라는 소프트웨어 데몬에 의해 각각 실행된다
- TaskTracker는 실제로 맵 또는 리듀스 Task를 인스턴스화하고, 진행 상황을 JobTracker에게 보고할 책임이 있다.
용어
- Job은 ‘Full Program’
- 데이터 집합을 통해 Mapper와 Reducer를 전체 실행
- Task는 데이터 조각을 통해 하나의 맵퍼 또는 리듀서를 실행
- Task attempt는 Task를 실행하기 위한 특정 인스턴스
- 적어도 Task가 있기 때문에 많은 Task attempt가 있을 것이다
- 만약 Task attempt가 실패하면, JobTracker에 의해서 다른 Task Attempt가 시작될 것이다
- Speculative execution(나중에 참조)는 완료된 Task들 보다 더 많은 Task를 시도할 수 있다.
Mapper
- 하둡은 네트워크 트래픽을 방지하기 위해, 메타 데이터의 일부분을 가지고 노드에서 처리한다
- 동시에 실행되는 여러 맵퍼는 각각 입력 데이터의 일부를 처리하는 단계를 포함한다
- 맵퍼는 Key / Value 쌍의 형태로 데이터를 읽는다
- 맵퍼의 0개 또는 그 이상의 Key / Value 쌍을 출력한다
- 맵퍼는 입력값의 Key를 사용하기도 하지만, 완전히 무시하기도 한다
- ex. 표준 패턴은 한 번에 파일의 라인을 읽는다
- Key는 라인이 시작되는 파일에 Byte Offset이다.
- Value는 라인 자체의 내용이다
- 일반적으로 Key는 관련이 없는 것으로 간주한다
- ex. 표준 패턴은 한 번에 파일의 라인을 읽는다
- 맵퍼의 출력형태는 Key / Value 쌍이어야 한다.
Upper Case Mapper
Let map(k, v) =
emit(k.toUpper(), v.toUpper())
('foo', 'bar') -> ('FOO', 'BAR')
('foo', 'other') -> ('FOO', 'OTHER')
('baz', 'more data') -> ('BAZ', 'MORE DATA')
Explode Mapper
Let map(k, v) =
foreach char c in v:
emit(k, c)
('foo', 'bar') -> ('foo', 'b'), ('foo', 'a'), ('foo', 'r')
Filter Mapper
Let map(k, v) =
if (isPrime(v)) then emit(k, v)
('foo', 7) -> ('foo', 7)
('bar', 10) -> Nothing
Changing Keyspaces
Let map(k, v) =
emit(v.length(), v)
('foo', 'bar') -> (3, 'bar')
Reducer
- 맵 단계가 끝나면, 중간 단계의 키 값을 기반으로 중간 값(Intermediate Values)를 리스트 형태로 조합
- 리스트를 리듀서로 전달
- 하나의 리듀서나 여러개의 리듀서가 존재할 것이다.
- Job 설정에서 정의되어 있다
- 중간 키와 연관되어 있는 모든 값은 같은 리듀서로 보내진다
- 중간 키와 그 값들의 리스트들은 키 순서대로 정렬되어 리듀서로 보내진다
- 이 단계는 ‘Shuffle’과 ‘Sort’
- 하나의 리듀서나 여러개의 리듀서가 존재할 것이다.
- 리듀서의 output은 0이거나 key / value 의 쌍이다
- 이 결과들은 HDFS에 저장된다
- 실제로 리듀서는 보통 input 키에 대해서 하나의 key / value 쌍으로 배출되어 쓰여진다.
Sum Reducer
let reduce(k, vals) =
sum = 0
foreach int i in vals:
sum += i
emit(k, sum)
('bar', [9, 3, -17, 44]) -> ('bar', 39)
Identity Reducer
let reduce(k, vals) =
foreach v in vals:
emit(k, v)
('bar', [123, 100, 77]) -> ('bar', 123), ('bar', 100), ('bar', 77)
예제) Word Count
let map(String input_key, String input_value) =
foreach word w in input_value:
emit(w, 1)
let reduce(String output_key, Iterator<int> intermediate_vals) =
set count = 0
foreach v in intermediate_vals:
count += v
emit(output_key, count)
Data Locality
- 가능하면 언제든지 하둡은 노드의 map task가 자신의 HDFS 노드에 있는 데이터 블럭에서 동작하는지를 확인하려고 할 것이다.
- 만약 불가능하다면 map task는 데이터를 가공하여 네트워크를 통하여 다른 노드로 데이터를 전달해야만 할 것이다
- map task가 끝나자마자 데이터는 네트워크를 통하여 리듀서들로 전달된다
- 비록 리듀서들이 map task와 물리적으로 같은 머신에서 동작하더라도 리듀서들은 데이터 지역성을 알 수 있는 개념은 없다.
- 즉, map task가 자신의 머신에 존재하는 리듀서로 보낸다는 보장은 못 함
- 일반적으로 모든 mapper들은 모든 리듀서들과 통신해야 한다.
병목현상
shuffle과 sort는 bottleneck인가?
- 셔플과 정렬단계는 병목현상을 보인다
- reduce 함수는 맵퍼가 끝날 떄까지 리듀서가 시작할 수 없다.
- 실제로, 일이 끝난 맵퍼들은 맵퍼에서 리듀서로 데이터를 옮기기 시작한다
- 마지막 맵퍼가 끝나면서 한번에 데이터를 이동시키는 병목현상을 완화한다
- 설정 가능하다. 맵퍼의 완료 퍼센트만큼 도달하면 리듀서로 데이터를 보내기 시작한다.
-
reduce함수는 모든 중간 데이터들의 이동과 정렬이 끝날 때 까지 시작하지 않는다.
느린 mapper는 bottleneck인가?
- 하나의 맵 태스크가 다른 태스크보다 느릴 수 있다.
- 머신의 성능이 좋지 못하는 등의 이유로
- 병목현상이 될 수 있다.
-
Speculative excution 사용하여 병목현상을 완화한다
- 매퍼가 다른 매퍼보다 심각하게 느리면 새로운 매퍼 인스턴스 생성하여 같은 데이터를 가지고 다른 머신에서 실행한다
- 느려진 작업을 끝내기 위해 첫번째 맵퍼들의 결과들을 사용할 수 있다
- 끝나지 않는 매퍼들은 kill할 수 있다.
잡의 생성과 실행
- 매퍼와 리듀서 클래스를 작성
- 잡과 이를 클러스터에 등록하기 위한 설정을 하는 Driver클래스 작성
- 매퍼, 리듀서, Driver 클래스 컴파일
javac -classpth <hadoop classpath> *.java
- 클래스 파일의 jar 파일 생성
jar cvf foo.jar *.class
- 하둡 클러스터에 잡을 생성
hadoop jar foo.jar Foo <in_dir> <out_dir>
댓글남기기