분산컴퓨팅(5)-Apache Hive
업데이트:
숭실대학교 박영택교수님의 “빅데이터분산컴퓨팅” 강의를 참고했습니다.
Hive
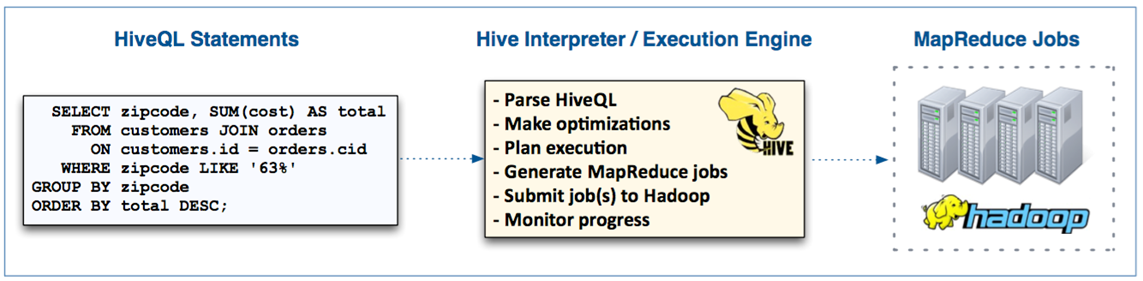
- Hive는 MapReduce 기반의 High-Level abstraction
- HiveQL은 SQL-like 언어를 사용
- Hadoop 클러스터에서 MapReduce 잡을 생성함
- Facebook에서 데이터 웨어하우스를 위해 개발되었음
- 현재는 오픈소스인 Apache 프로젝트
- Hive는 Client machine에서 동작
- HiveQL 질의문을 MapReduce job으로 변환
- jobs을 클러스터에 등록
Why Hive?
- MapReduce를 직접 작성하는 것보다 좀 더 생산적임
- java로 100라인 작성해야 할 것을 5라인의 HiveQL로 구현 가능
- 폭 넓은 사용자에게 대용량 데이터를 분석할 수 있는 기회 제공
- 소프트웨어 개발 경험이 필요 없음
- 기존 SQL 지식을 가진 사용자가 사용 가능
- 다른 시스템과의 상호 운용성 제공
- Java나 외부 Scripts를 통해 확장 가능
- 많은 BI 들이 Hive를 지원함
Load / Store
-
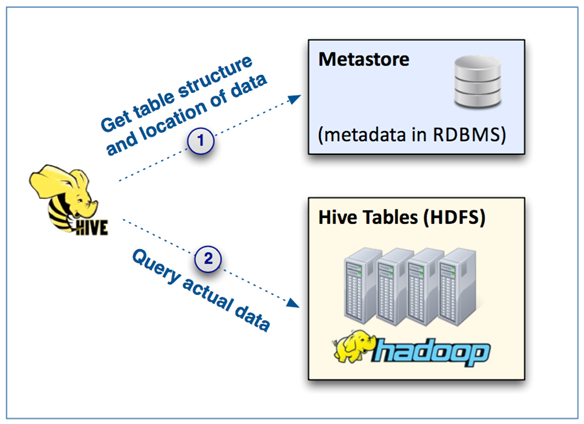
Hive는 데이터 포맷과 위치를 가지고 있는 metastore를 가지고 있음
- 질의문 자체는 파일시스템(HDFS)에 저장되어 있는 데이터에게 질의함
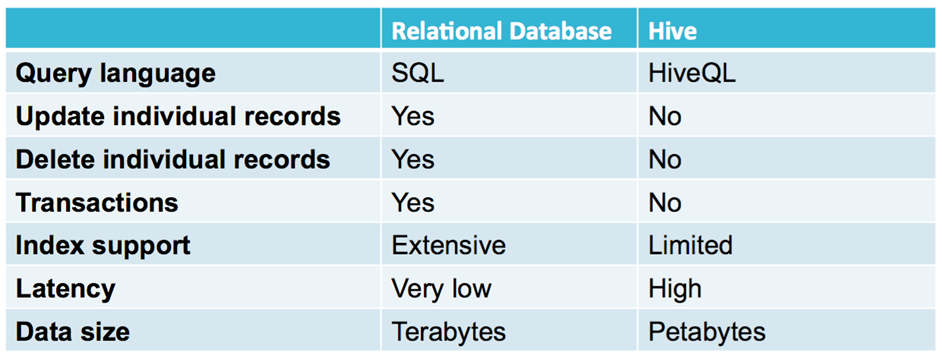
RDB와의 차이
Hive Shell 사용법
-
Hive shell에서 HiveQL 문장을 실행시킬 수 있음
- MySQL Shell의 interactive tool 과 유사
-
hive명령어로 Hive Shell을 실행- Hive Shell은
hive >프롬프트로 표현됨 - 각각의 명령어는 세미콜론
;으로 문장을 끝냄 -
quit을 통해 Hive Shell을 빠져나옴
- Hive Shell은
-
HiveQL 코드가 들어있는 파일을
-f옵션으로 실행 가능$ hive -f myquery.hql -
-e옵션을 통해 직접적인 HiveQL 실행 가능$ hive -e "SELECT * FROM users"
Table 생성
- 기본적으로 HDFS의
/user/hive/warehouse경로에 생성- 위 경로는 Hive의 warehouse 디렉토리
CREATE TABLE tablename (colname DATATYPE, ...)
ROW FORMAT DELIMITED
# 파일의 각 필드가 어떤 character로 구분되어 있는지 알려준다
FIELDS TERMINATED BY char
# 예를 들어 tab-delimited 데이터라고 하면, `FIELDS TERMINATED BY '\t'`로 적으면 된다.
STORED AS {TEXTFILE | SEQUENCEFILE | RCFILE}
# 마지막으로 파일의 포맷을 지정할 수 있다. STORED AS TEXTFILE 이 defualt이며,
# 지정하지 않을 경우 text format 이다.
# record 예제
# `FIELD TERMINATED BY ',';` 일 때
1, Data Analyst, 100000, 2013-05-21 15:52:03
MySQL to Hive via HDFS
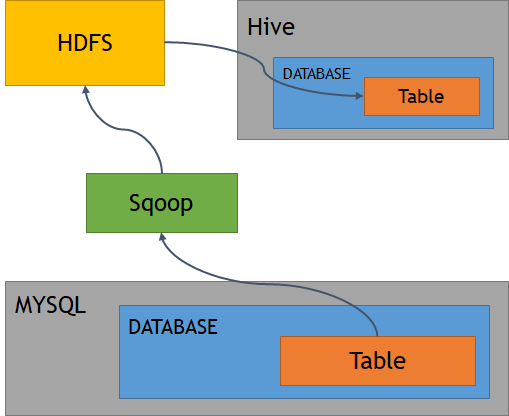
MySQL to HDFS
$ sqoop import \
--connect jdbc:mysql://localhost/retail_db \
--table categories --fields-terminated-by '\t' \
--username root --password cloudera
Hive DB Create
# Hive DB 생성
hive> create database hdfs_retail_db;
# DB 선택
hive> use hdfs_retail_db;
# Table 생성
hive> CREATE TABLE categories
(category_id INT, category_department_id INT, category_name STRING)
ROW FORMAT DELIMITED # 불러올 파일의 각 라인을 하나의 레코드로 구분
FIELDS TERMINATED BY '\t'; # 불러올 레코드를 tab으로 구분하여 컬럼에 저장
Hive Table에 데이터 불러오기
hive> LOAD DATA INPATH 'categories' INTO TABLE categories;
hive> SELECT * FROM categories LIMIT 10
MySQL to Hive directly
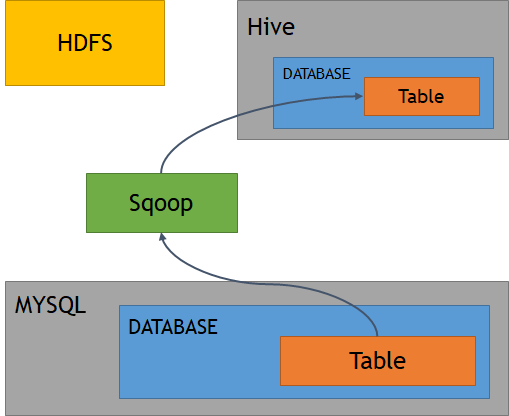
$sqoop import --connect jdbc:mysql://localhost/retail_db \
--username root --password cloudera \
--table categories --hive-database hive_retail_db \
--hive-import
Hive Query 예제
-
COUNT와GROUP BY에 대한 2개의 MapReduce Job이 실행
hive> SELECT category_department_id, COUNT(*) AS num --COUNT() : Job2--
FROM categories
GROUP BY category_department_id --GROUP BY : Job1--
ORDER BY num DESC
LIMIT 10;
Hive Join
SQL JOIN과 문법이 동일하다.
조인 방식은 다음 블로그를 참고하자.
댓글남기기