분산컴퓨팅(7)-PySpark
업데이트:
숭실대학교 박영택교수님의 “빅데이터분산컴퓨팅” 강의를 참고했습니다.
RDD
Resilient Distributed Dataset
- Resilient : 메모리 내에서 데이터가 손실되는 경우 다시 생성할 수 있다
- Distributed : 클러스터를 통해 메모리에 분산되어 저장된다
- DataSet : 초기데이터는 파일을 통해 가져올 수 있다
- RDD는 스파크에서의 기본적인 데이터 단위
대부분의 스파크 프로그래밍은 RDD를 통한 동작으로 구성된다
RDD 생성
- 파일, 파일의 집합을 통해 생성
sc.textfile("myfile.txt")
- 메모리에 있는 데이터를 통해 생성
sc.paralleize(arr)
- 기존 RDD 객체를 통해 생성
newRDD = RDD.map(func)
RDD Operations
- RDD 함수의 종류
- Actions : 값을 리턴
- Transformations : 현재의 것에 기초하여 새로운 RDD를 정의한다.
Transformations
- 이미 존재하는 RDD를 통해 새로운 RDD를 생성
- RDD는 Immutable
- 절대 변경할 수 없다
- 필요에 따라 데이터를 수정하는 시퀀스를 변환한다.
- 주요 Transformation 함수
map(func)-
filter(func)- partition의 수는 유지한다.
-
flatMap(func)- base RDD의 각 라인 별 element를 각 element 단위로 매핑
- partition 개수를 1로 만든다.

-
dictinct()- 중복 제거
Actions
- 주요 Action 함수
-
count(): RDD요소의 개수를 반환 -
take(n): RDD의 첫번째부터 n개의 record를 리스트로 반환 -
collect(n): RDD의 모든 record를 list로 반환 -
saveAsTextFile(path): RDD를 파일로 저장
-
Lazy Execution
RDD의 데이터는 action 함수로 인한 작업이 수행될 때까지 처리되지 않음
filter 연산은 lineage형태로 존재한다.
- 장점
- action으로 얻어지는 데이터만 가져오므로 메모리 효용성이 좋다.
- 단점
- action 이전의 연산들이 한번에 처리되므로 시간이 오래 걸린다.
Chaining Transformations
sc.textFile("test.txt")\
.map(lambda line:line.upper())\
.filter(lambda line:line.startswith('T'))\
.count()
Spark
-
Spark Context
-
Spark에서는 Driver와 excutors 사이에 통신이 일어남
-
driver는 Spark job을 가지고 있으며, 이를 실행하기 위해서는 excutors에게 Task를 나눠줘야 함
-
excutors 에서 작업이 끝나면 다시 driver에게 결과를 리턴
-
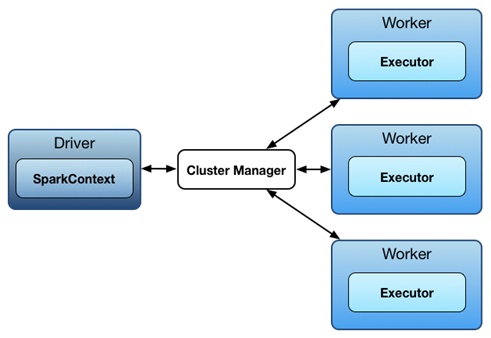
-
Spark App을 시작할 때, SparkContext 생성으로부터 시작
-
Master node 에서는 동작 가능한 cores를 사용자의 Spark App 전용으로 할당
-
사용자는 보통 Spark Context를 사용하여 RDD 생성
-
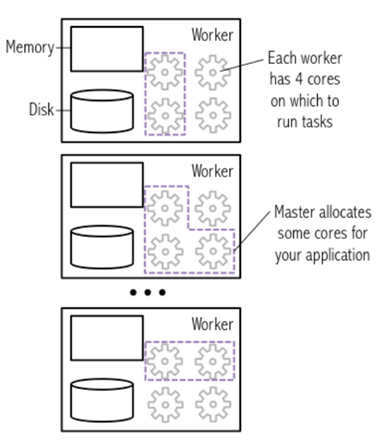
-
from pyspark import SparkConf, SparkContext conf = (SparkConf() .setMaster("local") # local mode .setAppName("My app") # App. name .set("spark.executor.memory", "1g")) # excutor memory allocate sc = SparkContext(conf = conf)
-
Reduce
reduce(func)
-
func은 항상 결합법칙과 교환법칙이 성립해야 한다.- 성립하지 않으면 partition 변경에 따라 값이 달라진다.
ReduceByKey
- reduceByKey
- 같은 node의 같은 key 값 기준으로 values를 미리 병합
- shuffling할 때, 네트워크의 부하를 줄여줌
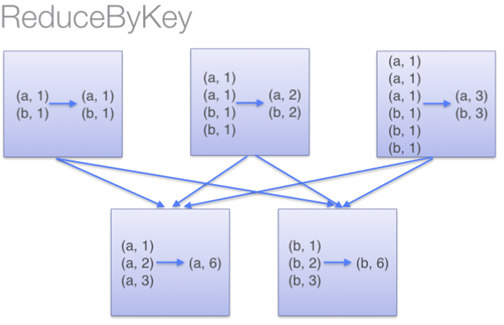
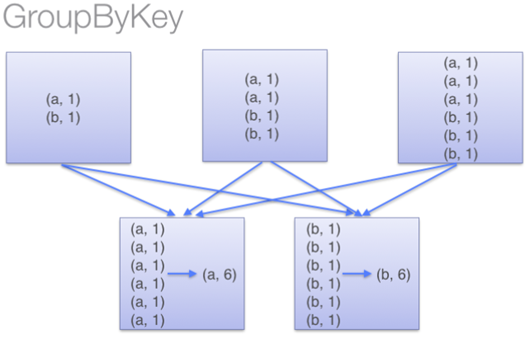
- GroupByKey
- 특별한 작업 없이 모든 pair 데이터들이 key값을 기준으로 shuffling 일어남
- 네트워크 부하가 많이 생김
- 하나의 key 값에 많은 데이터가 몰릴 경우 out of memory발생 가능
댓글남기기