LSM Tree
업데이트:
HBase는 데이터를 LSM Tree로 저장한다. LSM Tree가 어떻게 데이터를 저장하고, Compaction과 Bloom Filter 개념이 무엇인지 정리한다.
B+ Tree
관계형 데이터베이스에 주로 쓰이는 B+Tree 자료구조는 다음과 같은 시간복잡도를 가진다.
- Insertion : $O(logN)$
- Search : $O(logN)$
Log-Structured Merge Tree
배경
아이디어 1. Condense Data Query
DB에 저장할 쿼리를 Condense하게 하면
I/O가 적어지는 장점이 있으나, 추가적인 메모리가 소요되는 단점이 있다.
아이디어 2. Linked List
write 연산이 가장 빠른 자료구조는 linked list이다. 순차적으로 저장되기 때문
- Insertion : $O(1)$
Log는 Linked list로 구현된 개념이다.
단점은 Search 연산이 $O(N)$이라는 점이다.
이 연산의 속도를 빠르게 해야 하는데.. Linked List 자체로 Read 연산을 빠르게 하는 방법은 없다.
트리나 정렬된 배열과 같은 자료구조를 사용하면?
- Insertion : $O(logN)$
- Search : $O(logN)$
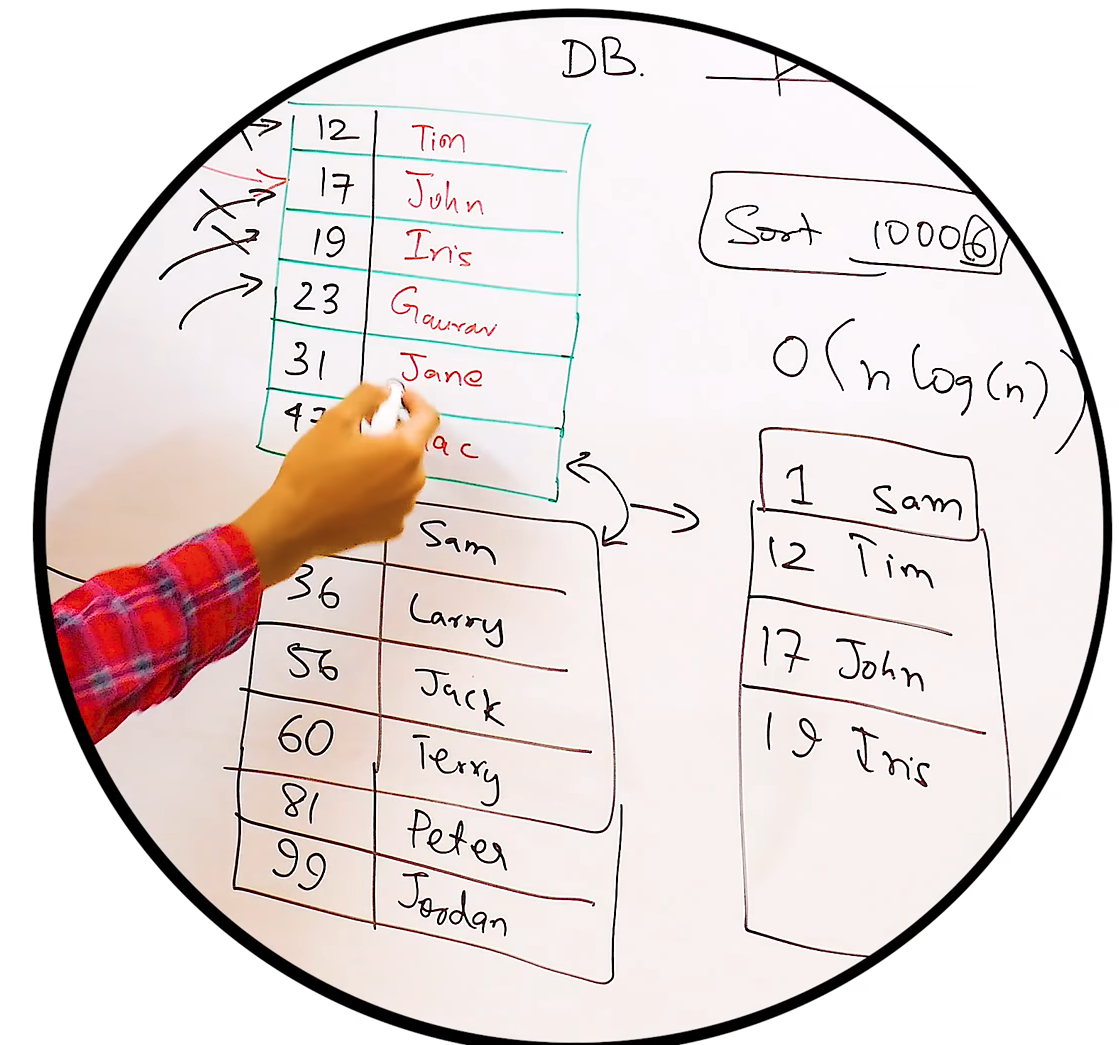
Sorted String Table (SS Table)
Linked List를 Sorted Array로 바꾸면 Read 성능을 향상시킬 수 있다.
클라이언트에서의 쿼리를 Log 형태로 메모리에 저장하다가, 메모리가 임계점에 다다르면 DB에 Sorted String Table로 Flush한다.

더 많은 데이터가 더해진다면, 동일하게 Log로 저장하다가, 꽉 차면 flush한다.
이 떄, 기존의 SS table과 merge하려면 $O(NlogN)$ 이라는 큰 시간이 걸린다.
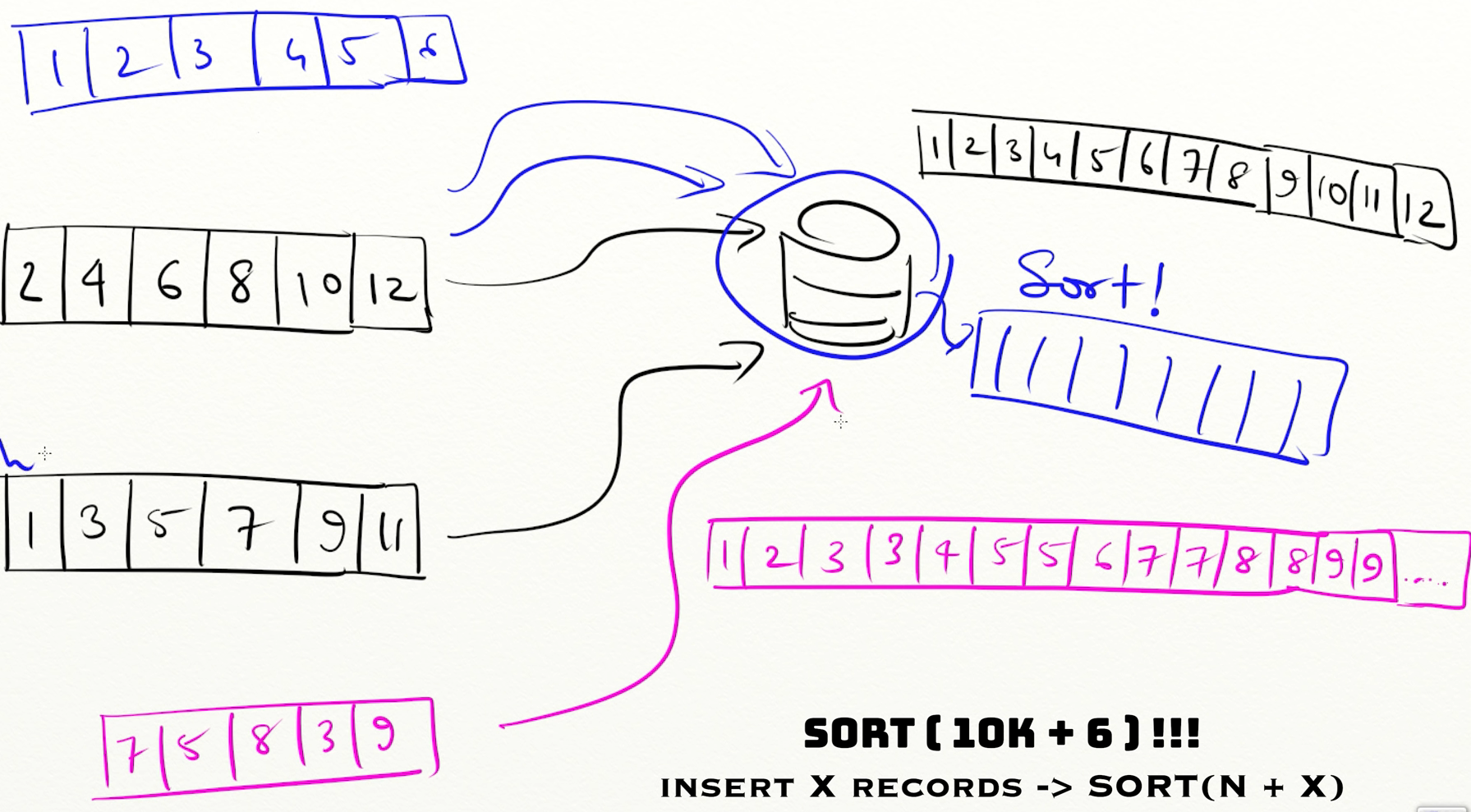
이 문제를 최적화하려면,
각 청크를 merging하지 않고 그냥 각 chunk를 ss Table로 flush하면 된다.
그런데 머지하지 않고 저장하면 또 문제가 생기는데,
Read 가 $O(logN * Number Of Chunk)$ 로 느려지게 된다.
- 전부 merge한 하나의 chunk이면 $O(logN)$
따라서, merge에 따르는 sort time이 너무 오래 걸리지 않는 시간 내에서, chunk를 merge해야 한다.
이때 각 SS table은 정렬되어 있으므로 two pointer를 활용하면 $O(N)$ 시간에 정렬이 가능하다.
그럼 언제 Chunk를 merge해야 하나??
영상에서는 각 chunk의 크기가 동일할 때, merge하라 한다
실제 HBase의 minor compaction은 사용자 옵션에 따라 사이즈의 최소,최대값 범위에 해당하는 HFile을 merge한다.
in HBase (추측)
HBase 에서는 Memstore라는 Log를 메모리에 유지하다가, flush연산 또는 일정 크기가 되면 HFile이라는 SS Table로 HDFS에 저장하고, minor compaction으로 각 HFile을 merge한다.
추측일뿐 확실하지 않습니다.
Compaction
Memstore를 flush할 때마다 HFile의 개수는 증가한다. 위에서 보았듯 파일의 수가 증가하면 Read연산이 느리진다.
파일 수가 늘어나면 적은 수의 파일로 merge한다. 이 작업은 파일이 limit로 설정된 크기를 초과하여 리전 분할이 될 때까지 계속된다.
Major Compaction
동일한 리전, 동일 컬럼패밀리의 모든 HFile을 하나의 파일로 merge한다.
많은 I/O를 동반하므로 주의해야 한다. hbase.region.majorcompaction.jitter 속성은 파일별로 major compaction이 수행되는 시점을 흩어지게 한다.
Minor Compaction
최근에 생성된 작은 파일들을 큰 파일로 merge한다.
디폴트로 파일의 수가 3~10개일 때 수행되도록 설정되어 있다.
Bloom Filter
HBase에서 특정 rowkey가 존재하는지 알아내려면 모든 파일의 블록을 메모리에 올려서 키를 발견할 때까지 스캔하는 수 밖에 없다.
- 블록이 크다면 Memstore의 flush를 강제하게 되므로 파일 수가 많아지게 된다.
블룸 필터를 사용하면?
- 해당 파일에 특정 rowkey에 해당하는 데이터가 있는지 즉시 알 수 있다.
- 모든 파일에 scan을 수행하지 않아도 된다!
- 블룸 필터가 파일이 있다고(positive) 판별해도, 실제 없을 수 있다(false) : false-positive
- 하지만, 파일이 없다고(negative) 판별하면, 실제로 있는 경우(false)는 발생하지 않늗다. : Never false-negative
Reference
- https://www.youtube.com/watch?v=_5vrfuwhvlQ
- 책 “HBase 완벽 가이드”
댓글남기기