DE 스터디(6) - Hadoop 
업데이트:
Parallel Computing
병렬 처리
- 여러 개의 코어를 사용하여 동시에 연산을 처리하는 것
- 크고 복잡한 문제를 작게 나누어 빠르게 해결
- 프로세서(코어)간 커뮤니케이션은 shared memory또는 message passing으로 이루어짐
- 병렬 처리의 종류
- 비트 수준(BLP)
- 프로세스가 처리하는 비트 수를 늘려서 속도 향상
- Instruction level parallelism
- 데이터 수준(DLP)
- 프로그램 루프에 내재된 병렬화
- task-level parallelism
- 비트 수준(BLP)
분산 처리
- 인터넷에 연결된 여러 컴퓨터들의 처리 능력을 이용하여 거대한 계산 문제를 해결하는 기술
- 가상의 대용량 고성능 컴퓨터(super virtual computer)를 구성하여 처리
- 컴퓨터들은 익명이며, 각자 메모리를 보유하고 있음
- 병렬 처리와 다르면서도 비슷한 개념(다중 코어 사용 연산은 병렬 처리와 동일)
- 분산 처리의 특징
- 고가용성(High Availability)
- 한 대의 노드가 고장나더라도 다른 노드에서 연산을 이어서 수행 가능하다
- 위치 투명성(Transparency)
- 네트워크에 연결된 노드들은 모든 자원을 로컬 자원처럼 다룰 수 있어야 함 -> 분산파일시스템(DFS) 제공
- 수평 확장성(Scale-Out)
- 노드 자체의 성능을 올리는 것이 아니라, 노드를 추가함으로써 시스템 성능 향상
- 고가용성(High Availability)
Cloud Computing 
- 정보를 자신의 컴퓨터가 아닌 인터넷에 연결된 다른 컴퓨터(데이터센터)에서 처리하는 기술
- 병렬 처리와 분산 처리를 활용
- 구성 가능한 컴퓨팅 자원(서버, 저장소 등)에 대해 어디서나 접근 가능
- 주문한 만큼 자원 사용
- 자원을 유연하게 운용 가능하고 self-design 용이
Hadoop
- High Availability distributed Object-Oriented platform
- 분산 컴퓨팅(클라우드 컴퓨팅) 기술을 활용한 대용량 데이터 분산 처리
- 빅데이터를 위한 범용 저장소 및 분석 플랫폼 제공
- 단일에서 수천 대의 머신으로 확장 가능하도록 설계
- java로 구현
장점
- 오픈소스로 라이선스 비용 부담 감소
- 시스템 중단 없이 장비 추가 용이(Scale-Out)
- 안정적이고 확장성이 높음
- 하둡을 기반으로 한 다양한 오픈소스 프레임워크가 구현되어 있음 (ex. spark)
- 일부 장비에 장애가 발생해도 전체 시스템에는 영향이 없음(fault-Tolerance)
- 대용량 데이터의 일괄(배치) 처리 가능
단점
- 저장된 데이터 변경 불가(안정성을 위함)
- 변경은 데이터 삭제 후 새로 생성하는 것
- 신속하게 작업해야 하는 실시간 데이터 처리에 부적합
- 설치와 설정이 어려움
구성 요소
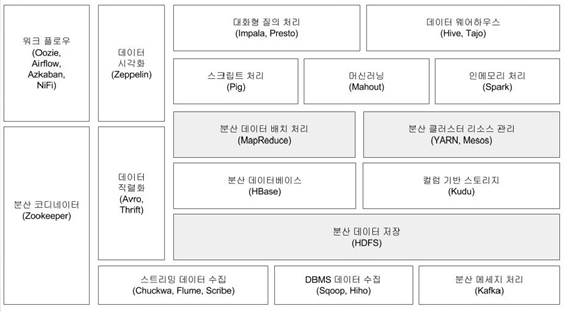
- 하둡 일반
- 다른 모듈을 지원하기 위한 공통 Component (자바 유틸리티)
- 하둡을 구동하기 위한 스크립트 포함
- HDFS (Hadoop Distributed File System)
-
YARN (Resource Manager, Job Scheduler)
- 전체적으로 job을 분배
- MapReduce
- ZooKeeper
- 분산 환경에서 서버 간 상호 조정이 필요한 서비스 제공 (분산 코디네이션)
- 부분 실패를 안전하게 처리할 수 있는 도구 제공
- Hbase
- HDFS상에서 구현한 컬럼 기반 분산 데이터베이스
- SQL을 지원하지 않음
- Flume
- 이벤트 기반의 대용량 데이터를 HDFS에 수집
- 데이터 수집, 전송, 저장 관리
- Kafka
- 실시간 데이터 스트림 관리 시스템. 분산 메세징 시스템
- publish / subscribe 모델
- load balancing(부하분산), Fault Tolerance 보장
- Hive
- 하둡 기반 데이터 웨어하우징 솔루션
- SQL과 유사한 HiveQL을 제공하며, HiveQL은 맵리듀스 잡으로 변환됨
-
Sqoop
- RDB, HDFS, DW, NoSQL 등 다양한 저장소의 데이터를 변환 전송
-
Oozie (Job Scheduler)
- MapReduce job이 잘 실행되고 있는지
-
Spark

스파크는 하둡 위에서도 실행 가능하고 독립적으로도 실행 가능하다.
HDFS 
개요
- 대용량 파일을 저장하기 위한 분산 확장 파일 시스템
- 스트리밍 방식으로 데이터에 접근
- 반응 속도보다는 시간당 처리량(throughput)에 최적화
- 간단한 결합 모델
- 데이터는 생성되거나, 원본으로부터 복사(수정되지 않음). 한번 쓰고 여러 번 읽는 모델에 적합
- 여러 컴퓨터에 파일을 나누어서 저장하며, 여러 곳에 중복 저장하여 안정성 확보
- 노드 장애가 발생할 확률이 높은 범용 하드웨어로 구성된 대형 클러스터에서 문제없이 실행되도록 설계되었음
HDFS 구성
- 블록
- HDFS의 파일을 나누는 단위로, HDFS로 읽거나 기록할 수 있는 데이터의 최소량
- 탐색 비용을 최소화하기 위해, 디스크 블록에 비해 큼
- 기본 블록 크기는 64MB (최대 128MB)
- 블록 추상화의 장점
- 파일 하나의 크기가 단일 디스크 용량보다 커질 수 있음
- 스토리지 서브시스템 단순화
- Fault tolerance, high-availability에 필요한 replication 구현에 적합
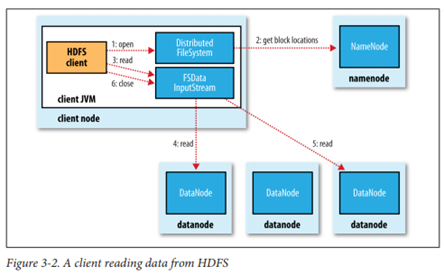
- 네임 노드, 데이터 노드
- HDFS는 마스터/슬레이브 구조로, 하나의 네임 노드와 여러개의 데이터 노드로 구성
- 네임 노드(마스터)
- 파일 시스템 트리에 포함된 파일/폴더의 메타데이터 유지
- 파일 namespace의 여러 기능(읽기, 닫기, 이름 바꾸기 등) 수행
- 데이터 노드
- 클라이언트가 요구하는 작업(읽기, 쓰기) 수행
- HDFS 클라이언트
- 사용자를 대신하여 네임 노드와 데이터 노드 사이에서 통신하고 파일 시스템에 접근
- 네임 노드 장애 복구 방법
- 메타데이터 백업
- 보조 네임 노드 운영
- HDFS 동작 방식
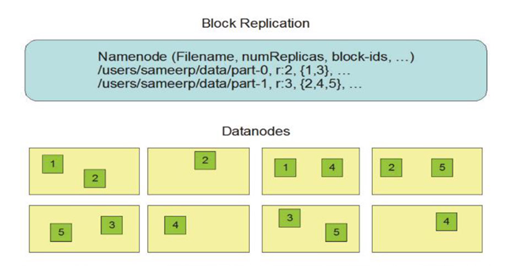
- hadoop 클라이언트가 네임 노드에 파일 생성을 요청한다
- 네임 노드는 클라이언트가 요청한 파일 정보에서 해당 경로에 대한 파일 정보를 메모리에 생성하고 락을 생성한다
- 네임 노드는 다시 파일 내용을 저장할 데이터 노드를 선택하여 데이터 노드 호스트 정보를 클라이언트에 전송한다
- 이 때, 데이터 노드 호스트 수는 hadoop 설정파일에 설정된 복제본 수 혹은 hadoop 클라이언트에서 추가 설정한 복제본 수가 된다.
- hadoop 클라이언트는 데이터 노드 호스트 정보 가운데 첫번째 정보를 이용해 데이터 노드로 데이터를 전송한다
- 전송되는 데이터는 데이터 노드 호스트 목록과 파일 데이터이다
- 데이터를 전송받은 첫번째 데이터 노드는 파일 데이터를 로컬 디스크에 저장한 다음 이를 두번째 데이터 노드에 전송한다
- 이런 식으로 파일 데이터는 네임 노드에서 보내준 모든 데이터 노드에 파일 데이터 복제본을 저장한다.
- 만약 파일 데이터 크기가 설정된 블록 크기보다 크다면 hadoop 클라이언트는 네임노드에 다음 블록을 저장할 데이터 노드 정보를 요청한다
- 파일 데이터가 데이터 노드에 모두 저장되면 네임노드는 생성한 파일 정보를 파일에 저장하고 락을 제거한다
- 네임 노드는 파일로 저장된 네임스페이스 정보를 보조 네임 노드로 전송한다
- 네임스페이스 정보는 네임 노드를 복원할 때 사용할 수 있다.
MapReduce
개요
- hadoop 클러스터의 데이터를 처리하기 위한 병렬 처리 프로그래밍 모델
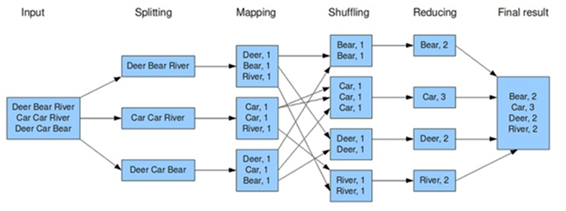
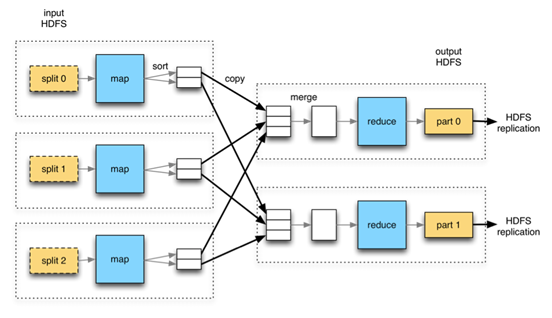
- MR 모델 단계
- Split : 전체 input data를 분할
- Map : 흩어져 있는(분할된) 데이터를 관련 있는 데이터끼리 묶어 임시 데이터 집합으로 변형 (분할된 데이터에 작업 수행)
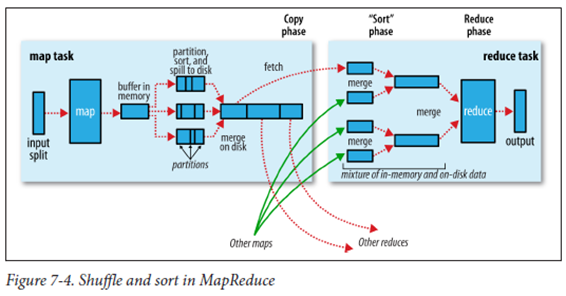
- Combiner : 네트워크를 타고 넘어가는 데이터를 줄이기 위하 Map의 결과를 정리 (Local Reducer)
- Partitioner : Map의 출력 결과 키-값을 해쉬 처리하여 어떤 Reducer로 넘길지 결정
- Shuffle(sort) : Map 함수의 출력 데이터를 파티셔닝/정렬하여 디스크에 저장 후, Reducer로 이동
- 중간 단계의 키 값을 기준으로 조합(리스트 형태)하여 Reducer로 전송
- 중간 키와 연관되어 있는 모든 값은 같은 리듀서로 보내짐
- 중간 키와 리스트들은 키 순서대로 정렬(hash값이 같으면 같은 Reducer)되어 보내짐
- Sort : Reducer로 전달된 데이터를 키 값 기준으로 정렬
- Reduce : Map단계에서 얻은 임시 데이터 집합에서 중복 데이터를 제거하고, 원하는 데이터 추출(집계). 하나의 결과 생성
- Output : Reducer의 결과를 정의된 형태로 저장
장단점
- 장점
- 단순하고 사용이 편리하다
- Map, Reduce 두 개 함수로 병렬처리 구현
- 유연성
- 특정 데이터 모델에 의존하지 않아 비정형 데이터 모델 지원 가능
- 저장구조와 독립적
- HDFS 외에도 다양한 저장 구조 지원
- 내고장성
- 데이터 복제 기반의 데이터 내구성 지원
- task 장애 시 각 task 재수행
- map의 결과를 중간 저장한 데이터로 재수행하여 효율성을 높였음
- 높은 확장성. Scale-out
- 단순하고 사용이 편리하다
- 단점
- 고정된 단일 데이터 흐름
- 복잡한 알고리즘을 구현하기 위해서는 여러번 MapReduce를 수행해야 함
- 스키마, 인덱스, 고차원 언어 미지원
- 데이터 무결성 결여
- 단순한 스케줄링
- 노드 성능이 낮거나 상이한 경우, 같은 job이 여러번 수행되는 경우가 있음
- 낮은 성능
- 주기적인 디스크 I/O 발생으로 RDB와 비교해 성능이 낮음
- 고정된 단일 데이터 흐름
기능
- 카운터 Counter
- Job에 대한 통계 정보 수집하는 채널로, 데이터 품질 통제나 app 수준의 통계 제공
- 문제 진단에 유용하게 사용
- 로그 출력을 일일이 확인하는 것보다 카운터 값 확인이 훨씬 수월하다
- 카운터 종류
- 내장 카운터 : Task 카운터, Job 카운터
- 사용자 정의 자바 카운터 : 자바 enum으로 정의한 카운터
- 사용자 정의 스트리밍 카운터
- 정렬 Sort
- 부분 정렬
- MapReduce는 기본적으로 키를 기준으로 입력 레코드를 정렬함
- 전체 정렬
- 출력의 전체 순서를 고려하여 파티셔님하고, 파티션 내부 정렬
- 파티션 크기는 균등하도록 조정해야 효율이 높음
- 데이터 분포는 샘플링으로 판단
- 2차 정렬
- 부분/전체 정렬로 정렬되지 않는 키-값 정렬
- 원래 키와 원래 값으로 조합 키를 만들어 정렬하되, 파티셔닝과 그룹화는 원래 키만 고려
- 부분 정렬
- 조인 Join
- map-side 조인
- 데이터가 map 함수에 도달하기 전에 수행
- 특정 키에 대한 모든 레코드는 동일한 파티션에 존재해야 함
- 동일한 리듀서 개수, 동일한 키, 분리되지 않는 출력 파일일 때 사용 가능
- Reduce-side 조인
- 특별한 제약 조건은 없으나, 조인될 데이터가 모두 셔플 단계를 거쳐야 하므로 비효율적
- map-side 조인
MapReduce Job
-
Job(Application)
- 하둡 클라이언트가 수행하는 작업의 기본 단위로, Map task와 Reduce task로 나누어 실행
-
Job의 구성
- 입력 데이터
- 맵리듀스 프로그램
- 설정 정보
-
Map task
- MR job 입력은 input split(고정된 크기의 조각)으로 분리하며, hadoop은 각 split마다 map task를 생성하여 map함수로 처리
- map task의 적절한 split 크기는 HDFS 블록의 크기(단일 노드에 해당 블록이 모두 저장된다고 확신할 수 있는 입력 크기)
- split이 작으면 작업 부하가 분산되어 성능이 높아지나, 너무 작으면 map task를 위한 오버헤드가 증가하여 작업이 느려질 수 있음
- 일부 파일은 split되지 않고 처리해야 할 수 있음 (단일 map으로 처리)
- map task 결과는 로컬 디스크에 임시 저장하고, job이 끝나면 삭제 (속도 저하의 근본적 원인)
- hadoop은 HDFS내의 입력 데이터가 있는 노드에서 map task를 실행할 때 가장 빠르게 작동(데이터 지역성 최적화)
- 데이터 이동 네트워크 부하 최소화
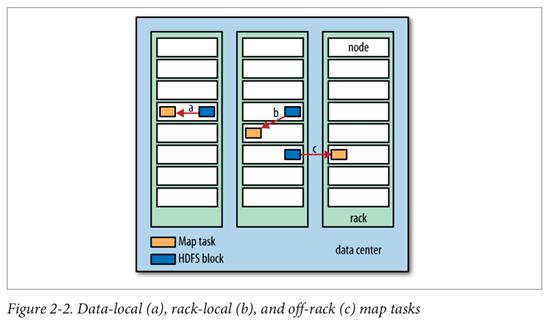
- MR job 입력은 input split(고정된 크기의 조각)으로 분리하며, hadoop은 각 split마다 map task를 생성하여 map함수로 처리
-
Reduce task
- 모든 Mapper의 출력 결과를 (네트워크를 통해) 입력으로 받으므로, 데이터 지역성의 장점은 없음
- Reduce의 결과는 안정성을 위해 HDFS에 저장
- Reduce task 수 지정 가능
- Reduce 개수 만큼 Map의 결과물을 분배하며, 동일한 키는 같은 Reducer에 전달(Shuffle)
- Reducer가 없을 수도 있음(Mapper only)
- 기본 값은 1개지만, 1보다 크게 설정하는 것이 좋음
MapReduce Job 실행
- 클라이언트
- MapReduce Job 제출
- Yarn 리소스 매니저
- 클러스터 상에 계산 리소스 할당 제어
- Yarn 노드 매니저
- 클러스터의 각 머신(노드)에서 계산 컨테이너 시작하고 모니터링
- App. 마스터
- job을 수행하는 각 task 제어
- HDFS
- 다른 단계 간 Job 리소스 파일 공유
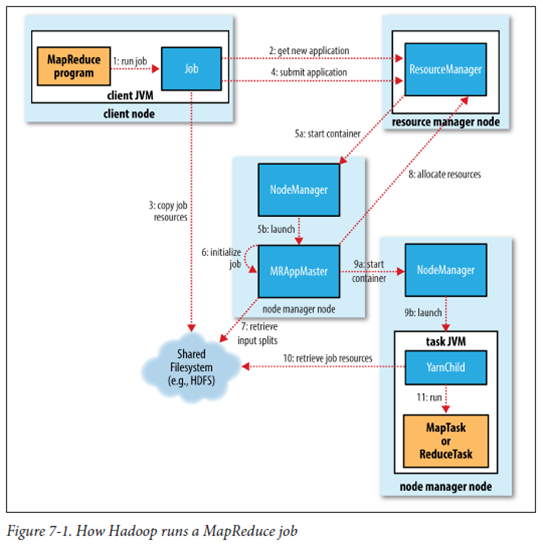
- hadoop 클라이언트가 Resource Manager에게 어플리케이션을 제출한다
- Node Master를 통해 Application Master를 실행한다
- Application Master는 Resource manager에게 자신을 등록한다
- Application Master는 Resource manager를 통해 어플리케이션을 실행할 컨테이너 할당을 요청한다
- Application Master는 Node master에게 할당된 컨테이너를 실행하라고 요청한다
- 컨테이너에서 실행되는 어플리케이션은 상태정보를 Application Master에게 전송한다
- 클라이언트는 어플리케이션에서 실행상태 정보를 얻기 위해 Application master와 직접 통신한다
- 어플리케이션이 종료되면 Application Master는 Resource manager 자신을 제거하고 셧다운 된다
Oozie
- 종속 관계에 있는 여러 Job을 흐름에 따라 실행해 주는 시스템
- Workflow 엔진과 Coordindator 엔진으로 구성
- Workflow
- 다른 형태의 Hadoop Job(MapReduce, HIve 등)을 구성하는 작업 흐름을 저장하고 실행
- Coordinator
- 미리 정의된 일정과 데이터 가용성을 바탕으로 Workflow job 실행
- Workflow
- 쉽게 확장 가능하도록 설계되었으며, 시간 효율이 높음 (성공한 부분은 다시 실행하지 않음)
Yarn
개요
-
Hadoop의 클러스터 관리 시스템으로, hadoop 2 버전에서 처음 도입
-
MapReduce 외 다른 분산 컴퓨팅 도구도 지원
-
클러스터 자원을 요청하고 사용하기 위한 API 제공
- 사용자는 고수준 API를 작성하므로, 자원 관리의 자세한 내용은 알 수 없음
-
클러스터 저장 계층(HDFS, HBase) 위에서 실행
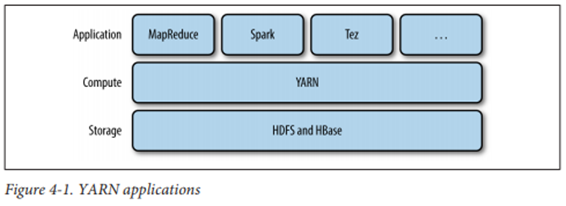
-
Yarn 구성
- 리소스 매니저
- 클러스터 전체 사용량 관리(Scheduler - 자원 분배 규칙 설정). 노드 매니저, app. 마스터와 함께 동작
- 노드 매니저
- 클러스터 각 노드마다 실행되며, 컨테이너를 구동하고 모니터링
- App. 마스터
- app. 실행 및 관리를 담당하며, app. 마다 존재
- 컨테이너
- 클러스터 노드의 메모리, CPU코어, 디스크 등 물리적 자원
- 리소스 매니저
-
Yarn의 Application 수행 과정
- 클라이언트가 리소스 매니저에 접속해 app. 마스터 프로세스 구동 요청
- 리소스 매니저가 app. 마스터를 실행할 수 있는 노드 매니저를 찾음
- App. 마스터가 단순 계산을 하나의 컨테이너에서 수행하고 결과 반환 후 종료
- 리소스 매니저에 더 많은 클러스터(컨테이너) 자원을 요청 후 분산 처리 수행
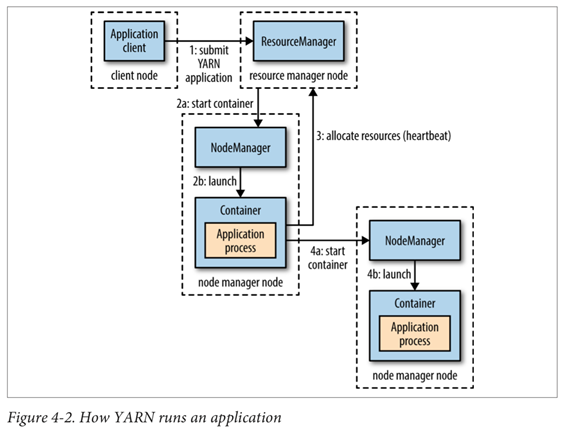
-
자원 요청
- 유연한 자원 요청 모델
- 각 컨테이너에 필요한 컴퓨터 자원 용량(메모리, CPU) 외에도 지역성 제약(?) 표현 가능
- App. 실행 중에는 아무 때나 자원 요청 가능
- 처음에 모두 요청(spark)
- 동적으로 자우너 추가 요청(MapReduce)
- 유연한 자원 요청 모델
-
app. 구분 : 사용자가 실행하는 Job 방식에 따라
- 사용자 Job 당 app. 하나 (MapReduce)
- Workflow나 사용자 Job Session 당 app. 하나 (Spark)
- 서로 다른 사용자들이 공유할 수 있는 장기 실행 app. (Impala)
Job Tracker / Task Tracker
- Hadoop 1 버전에서 사용
- JobTracker
- 태스크 관리로 시스템에서 실행되는 모든 Job 관리
- TaskTracker
- 태스크를 실행하고 진행 상황을 JobTracker에 전송
Yarn 장점 (JobTracker 대비)
- 확장성
- app. 마스터와 리소스 매니저를 분리하여 더 많은 노드와 태스크 관리 기능
- app. 마스터는 해당 app.이 실행될 때만 존재
- 가용성
- Divide and Conquer (분할 후 정복)
- 리소스 매니저와 app. 마스터 모두에 고가용성 제공
- 효율성
- 노드 매니저는 리소스 풀을 관리하기에 유동적으로 자원 할당 가능
- app. 은 필요한 만큼 자원 요청
- 다중 사용자
- MapReduce 외 다양한 app. 수용 가능
- 다른 버전의 MapReduce 동시 실행 가능
Yarn Scheduler
-
정해진 정책(규칙)에 따라 app. 에 자원 할당
-
스케줄링 규칙은 사용자가 선택 가능
-
스케줄링 옵션
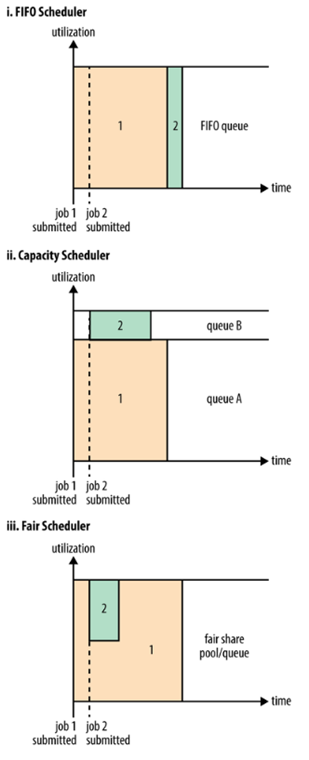
- FIFO
- app. 을 큐에 하나씩 넣고 제출된 순서에 따라 실행
- 이해하기 쉽고, 설정할 필요 없음
- 대형 app. 이 클러스터 자원을 모두 점유할 우려가 있어 공유 환경에서는 적합하지 않음
- Capacity Scheduler
- 작은 job을 분리된 전용 큐에서 처리
- Job을 위한 자원을 미리 예약하는 방식으로 전체 클러스터의 효율성이 떨어짐
- Fair Scheduler
- 실행 중인 모든 Job의 자원을 동적으로 분배
- 대형 job이 실행되는 중에 작은 job이 들어오면 클러스터 자원을 작은 job에 할당
- 작은 job이 끝난 후에는 다시 큰 job이 전체 가용량 확보
- FIFO
댓글남기기