DE 스터디(7) - Spark
업데이트:
Spark 개요 
-
인메모리 분산 데이터 분석 시스템 (클러스터 컴퓨팅 프레임워크)
- RDD 데이터 타입(변하지 않는 데이터 셋) : RAM을 ROM처럼 활용
- MR 모델을 대화형 명령어 쿼리나 스트리밍, 머신 러닝이 가능하도록 확장
- Scala 언어로 구현되어 있으며, 자바 가상 머신(JVM)으로 실행됨
- MapReduce 과정을 알아서 처리해 줌
Spark Application 실행 구조
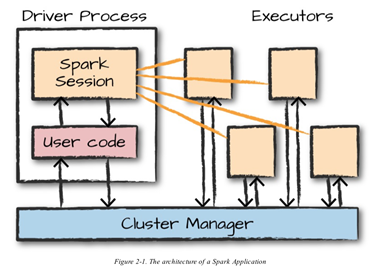
-
드라이버
-
사용자가 짠 프로그램의 main()이 실행되는 프로세스
- SparkSession : 드라이버 프로세스로 Spark app.과 1:1로 대응됨
- 드라이버가 종료되면 Spark app. 도 종료됨
- 역할
- 사용자 프로그램을 태스크로 변환
- 익스큐터 태스크 스케줄링
- 스파크 app. 정보 관리
태스크(task) : 물리적 실행 단위/계획으로, 하나의 노드에서 실행되는 단위 작업
-
사용자가 짠 프로그램의 main()이 실행되는 프로세스
-
익스큐터
- 주어진 Spark 작업의 개별 태스크들을 실행하는 작업 실행 프로세스
- Spark app. 실행 시 최초 한 번 실행되고, app.이 끝날 때까지 동작
- 역할
- 태스크를 실행하여 작업 결과를 드라이버에게 돌려줌
- 익스큐터 안의 블록 매니저 서비스를 통해 캐시 RDD를 저장하는 메모리 저장소 제공
- 클러스터 매니저
- 드라이버 실행 관리
- Spark에 붙이거나 뗄 수 있는 형태의 구성 요소
- 다양한 외부 매니저 자원
-
Spark Session과 언어 API
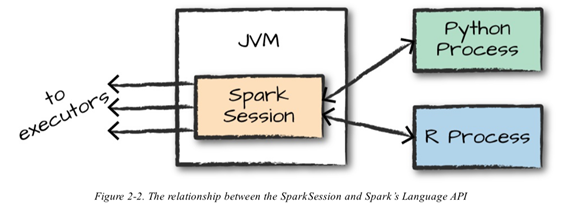
- 다양한 언어로 스파크 코드 실행 가능
- Spark Session은 익스큐터에 태스크를 전달하기 전에 JVM에서 실행할 수 있는 코드로 변환
- Spark Application 실행 단계
- 드라이버 위에 있는 사용자 코드가 RDD 논리 그래프 생성
- 논리 그래프를 실행 계획(태스크)로 변환
- 태스크 스케쥴링 및 실행
Spark 등장 배경 (vs. MapReduce)
- MR 단계를 여러번 거치면 중간 결과물을 HDFS에 저장, 출력하는 방식으로 I/O 리소스를 많이 잡아먹게 됨
- MR은 API가 복잡하고, 그에 따라 유지보수가 쉽지 않음
- 데이터 분석 중간 과정을 In-memory로 처리하면 빠르지 않을까?
- Piccolo(RAM) 기반 데이터 처리(Spark 이전의 메모리 처리 시도)
- RAM 데이터는 휘발성이 높음(데이터 변동 가능성)
- 데이터 유실에 대비해, replicate, checkpoint 등의 작업 필요
- RAM 기반 처리 효율성이 떨어짐
- Spark는 RDD 구조로 이를 개선함
Why Spark?
- 빠른 속도(MR 모델의 약 100배)
- RDD의 특징
- 분산 처리 시스템으로 대용량 분석 가능
- 쉬운 사용
- 다양한 언어 지원
- Scala, Java, Python (+SQL, R)
- 로컬 모드와 분산 처리 모드의 코드가 동일(코드의 유사성)
- MR보다 간단한 코드 구성
- 다양한 언어 지원
-
범용성
- Hadoop(Hbase, Hive) 등 여러 플랫폼에서 동작
- Component 간 상호 연동이 잘 됨
Spark의 메모리 활용
- RDD(data) 저장
- 셔플 및 집합 연산 버퍼
- 사용자 코드
Spark 장애 내구성
- 오류가 발생하거나, 노드가 느려질 경우 느려진 작업을 다른 노드에서 재실행
- 최대 효율을 위한 조치이나, 중복 작업 가능성 존재
Spark 단점
앞으로 해결 가능한 사항
- 높은 메모리 요구
- 연속적인 처리에 유리
- 간단한 분석의 경우 타 모델과 큰 차이 없음
- 딥 러닝의 경우(빠르기는 하지만) 실시간 처리 어려움
- Spark에서 GPU 프로그래밍은 아직 불가능.
- 딥러닝은 아직 GPU로 쓰고 있다
- 불안정성
- RAM에서의 처리로 데이터 유실 가능성
RDD
Resilient Distributed Dataset
- 분산되어 있는, 변경 불가능한 데이터 모음
- 사용자 정의 클래스 포함 모든 객체 형태 지원
- 다양한 input과 output 포맷 지원(txt, csv, json, HDFS 등)
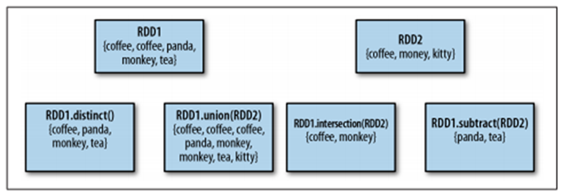
RDD 연산
- Transformation (RDD to RDD)
- 존재하는 RDD에서 새로운 RDD를 만들어 냄(원본 보존. 수정 아님)
- 새로운 RDD의 포인터(레퍼런스) 리턴
- 입력 RDD의 개수는 제한 없음
- Action (RDD to Other type)
- RDD 기반으로 실제 연산 수행(총합, 개수, 평균, 연산, 값 저장 등)
- 드라이버 프로그램(사용자 제어 프로그램)에 값을 반환하거나 외부 저장소에 저장
- 실제로 결과 값을 내야 하므로, Transformation이 계산을 수행하도록 강제
RDD 연산의 특징
-
RDD 연산은 사용자로부터 전달받은 함수(연산 규칙)을 실행하는 것으로, 함수 전달 방법은 언어마다 조금씩 다름
- Spark app. 은 내부적으로 연산들의 관계를 RDD 논리 그래프(Linearge)로 표현하고, 드라이버는 연산을 task로 전환하여 실행하게 됨
- task가 반드시 RDD 논리 그래프와 1:1로 매치되는 것은 아님
spark 2.0 버전부터는 RDD 연산을 직접 하는 경우가 드물다.
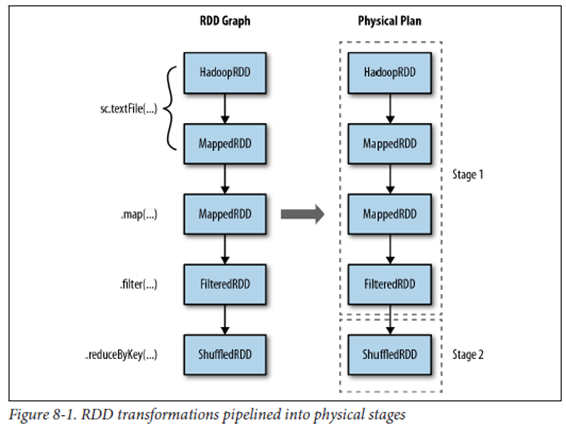
- DAG(Directed Acyclic Graph) : 지향성 비순환 그래프로, tree구조와 유사한 형태
- task가 반드시 RDD 논리 그래프와 1:1로 매치되는 것은 아님
-
Lazy-Excution(여유로운 실행)
-
Transformation 시에는 메타데이터에 연산 요청을 기록해 두었다가, Action 명령어를 만나면 한꺼번에 실행하여 불필요한 연산을 줄임
-
Action이 실행될 때마다 새로운 연산 수행
- 연산을 그룹화해서 데이터를 전달하는 횟수를 줄이기 위함
-
Lineage(계보) : 동일 RDD를 생성하는 설계도 = RDD 관계도(그래프)
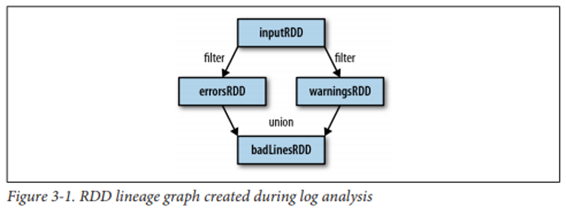
-
영속화(캐싱)
- RDD는 새로운 action을 호출할 때마다 전체 RDD를 다시 계산함(큰 데이터의 저장 비효율성을 줄이기 위함)
- 사용자는 여러 action에서 동일한 RDD를 재사용하고 싶을 경우, 결과 유지(데이터 저장)를 요청할 수 있음
- 목적에 맞는 다양한 수준의 영속화 제공
- 메모리 용량 이상을 캐시할 경우, LRU(Least Recently used) 캐시 정책에 따라 오래된 파티션을 자동으로 버림
- 캐시된 데이터 직접 삭제 가능
- RDD가 캐시되어 있을 경우, 스케쥴러는 RDD 관계도를 제거할 수 있음
-
기타 사항
- RDD 타입
- 어떤 함수들은 특정 RDD에서만 수행 가능(수치연산 등)하기 때문에, RDD타입을 잘 확인해 보는 게 중요
- 파티셔닝
- 적절한 데이터 분할은 네트워크 부하(비용)를 최소화하고, 프로그램 성능을 극대화할 수 있음(셔플링 연산 최소화)
- 파티셔닝이 한번만 발생하도록 함
- 모든 RDD의 key-value 쌍에 대해 가능
-
외부 프로그램과 연결
- pipe를 사용하여 다른 프로그램과 RDD 데이터를 주고받을 수 있음
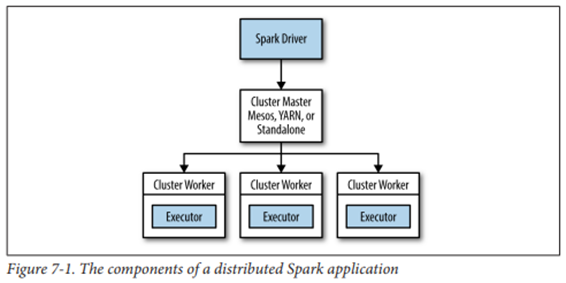
Spark management
하둡의 리소스 관리와 유사하다.
Cluster Manager
- Yarn, Mesos 등 타 스케줄러 사용 가능
- 단독 스케줄러 지원
- 로컬 CPU 코어와 메모리 용량을 고려하여 자동으로 master와 worker(executor) 설정
- master 1개와 여러개의 worker
- Executor의 메모리와 코어 수 직접 지정 가능
- 로컬 CPU 코어와 메모리 용량을 고려하여 자동으로 master와 worker(executor) 설정
- Spark Executor는 스케줄러의 자원(Cluster Worker) 안에서 실행
드라이버 프로그램
- Spark app. 의 main함수 보유
- RDD를 정의하며, RDD 연산 수행
- 노드(executor) 관리
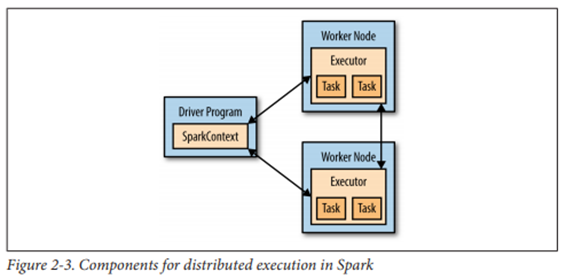
- SparkSession, SparkContext 객체를 통해 스파크에 접속
- 연산 작업 수행을 위해, 원하는 함수를 작성해 연산 함수에 인자로 보내는 식으로 작동
- Spark 중지 (shutdown)
- stop() 메소드 (python)
- shutdown 이후에는 객체를 사용할 수 없음
Yarn에서 Spark 실행
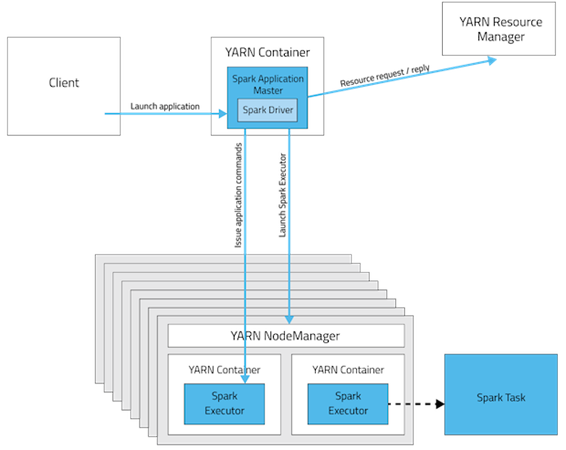
- Yarn 배포 모드
- Yarn 클라이언트 모드
- 클라이언트에서 드라이버 실행
- 대화형 component(ex.spark-shell) 필요
- 디버깅 출력을 바로 볼 수 있어 Spark 프로그램을 처음 짤 때 유용
- Yarn 클러스터 모드
- 드라이버가 클러스터의 Yarn app. 마스터에서 실행
- 전체 app. 이 클러스터에서 실행되므로 운영에 적합
- App. 마스터에 문제가 생기면 해당 app. 다시 실행 시도
- Yarn 클라이언트 모드
- Spark 드라이버와 task를 수행하는 노드가 Yarn 컨테이너 안에서 동작하므로, Yarn 컨테이너 메모리는 충분히 커야 함
- Yarn 메모리와, Spark에서 설정한 메모리 크기가 합쳐진 만큼의 자원 점유
Spark Components
Spark Stack
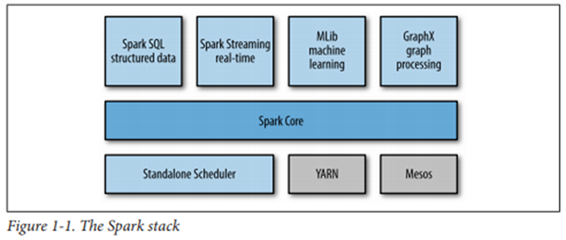
- 인프라 계층
- Spark를 기동하기 위한 인프라(Scheduler) = Spark 관리 계층
- Spark Core
- 다른 라이브러리들의 기반
- Spark Library
- 특정한 기능을 목적으로 만든 모듈로, Spark Core를 활용함
Spark Core
- 스케줄링, 메모리 관리, 장애 복구, 저장장치 연동 등 기본적인 기능으로 구성됨
- RDD API의 기반
- Core 엔진을 중심으로 필요한 component를 올려 사용
Spark2 Components 
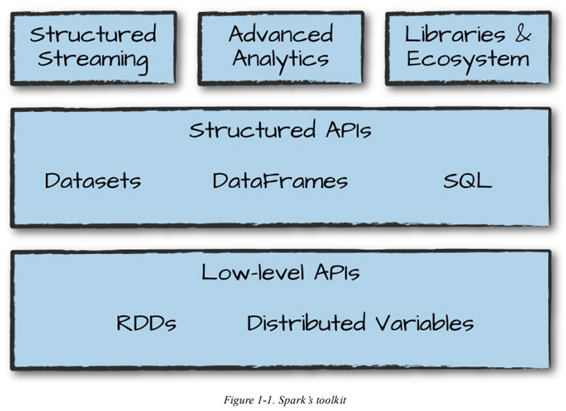
- RDD 구조를 활용한 Structured RDD 강화
- DataSet(DataFrame)을 중심으로 연산이 이루어짐
- (Java, Scala) DataFrame은 사실상 삭제. 호환을 위해 코드상에만 남아있음
DataFrame
- 잘 정의된 Row와 Column을 가지는 분산 테이블 컬렉션
- 레코드의 스키마 정보(Column 타입 정보)를 가지고 효율적인 형태로 데이터 저장
DataSets
-
RDD + type & 스키마
- Type-safe structured RDD
- DataFrame은 Dataset[Row]로 간주되며, DataSet의 부분집합
- Row타입은 ‘연산에 최적화된 인메모리 포맷’
- Java와 Scala 언어만 지원
- 컴파일 타입 안정성 때문
- DataFrame 생성/조작 Object Class 제공
- 다수 에러가 컴파일 시점에 감지되어 런타임 에러를 줄일 수 있음
- 높은 수준의 추상화 API로 간결한 코딩 가능
구조적 API 실행 과정
구조적 api : DataFrame, Dataset
- 사용자 코드 작성
- 논리적 실행 계획으로 변환
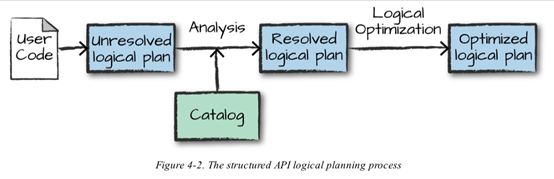
- 논리적 실행 계획을 물리적 실행 계획으로 변환 (실행 최적화)
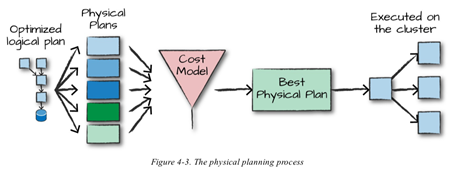
- 클러스터에서 물리적 실행 계획(RDD) 처리
Spark SQL
-
Spark와 RDB의 통합
-
구조적 API와 RDB table을 연결하는 데에 주로 사용
-
Spark SQL의 세 가지 기능
- DataFrame 추상화 클래스 제공
- 다양한 구조(포맷)의 데이터 I/O(JSON, Hive 등)
- 프로그램 내부 또는 표준 DB 연결(JDBC/ODBC)을 통해 외부 툴에서 SQL 사용
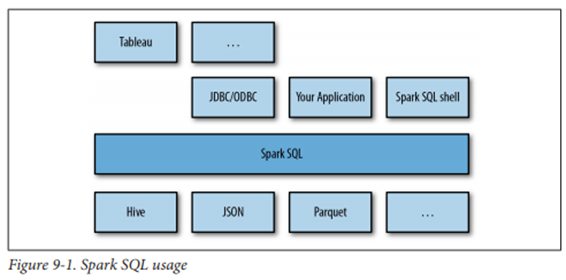
Spark ML(MLlib)
-
머신러닝 기능을 모아 놓은 알고리즘 라이브러리
- 클러스터에서 잘 돌아가는 병렬 알고리즘 보유(분산 RF, K-means 등)
- 하나의 모델을 분산 대용량 데이터셋에 적용할 때 효율적
- 클러스터 전체를 활용하고 실행
-
구성요소
- 변환자 : 원시 데이터를 다양한 방식으로 변환하는 함수
- ex. one-hot encoding
- 추정자
- 데이터 정규화 (변환 초기화)
- 모델을 학습시키기 위해 사용하는 알고리즘
- ex. model fitting
- 평가기 : 모델 성능 테스트
- ex. model evaluation
- 변환자 : 원시 데이터를 다양한 방식으로 변환하는 함수
-
파이프라인 API
- 데이터세트를 변환하고, 모델을 예측하는 과정의 모음
Spark Streaming
-
실시간 데이터 스트림 처리
맵리듀스 속도가 100배 빨라졌기 때문에 가능해졌다
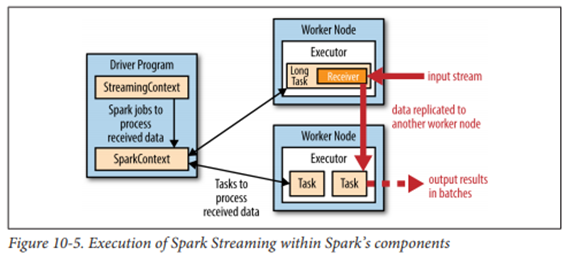
-
마이크로배치 아키텍처
- 연속된 데이터를 시간 간격별 배치로 분리
- 입력 배치는 RDD 형태
- 처리 후 외부 시스템으로 전달
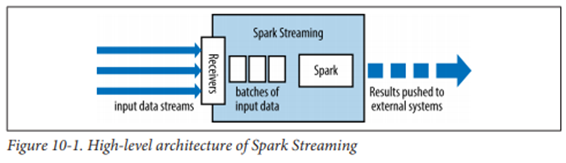
-
Dstream(Discretized stream, 이산 스트림)
- 시간에 따라 도착한 데이터(RDD)의 연속적인 모음(큐 방식)
- Dstream의 데이터 중, 관심 있는 일부 데이터를 추출해 분석을 진행하게 됨
- 다양한 형태의 Data I/O를 지원하며(카프카, 플럼, 트위터 등), 해당 데이터의 내장 지원 모듈 활용 가능
- 새로운 Dstream을 만드는 Transformation 연산과 외부 시스템에 데이터를 보내는 결과 연산 지원
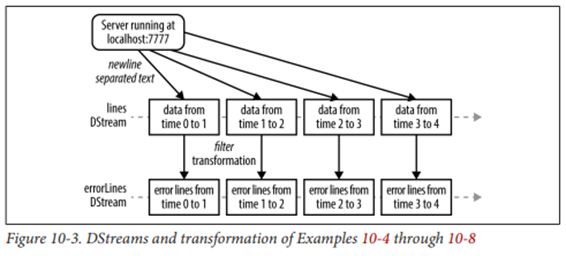
Structured Streaming (Spark 2)
-
데이터 스트림을 테이블로 표현

-
모든 처리를 Table로 한다
-
입력 테이블
- 새 데이터가 들어오면 테이블이 계속 커지며, 장기 실행 쿼리를 통해 지속적으로 처리
-
결과 테이블
- 입력 테이블에서 처리된 쿼리 결과 포함
- 외부 DB에 내보내기
-
Trigger
- 데이터가 입력 테이블에서 처리되는 타이밍 (default = 0)
- 값이 0인 경우, 데이터 입력 즉시 처리 시도
-
처리 모드
- 추가 모드
- 마지막 쿼리가 실행된 이후 결과 테이블에 추가된 행만 처리(트리거 간격 경과 시마다 새 데이터 처리)
- 전체 모드
- 가장 최근의 트리거 실행뿐 아니라 모든 실행의 데이터를 테이블에 포함(단, 무제한 커지지는 않음)
- 추가 모드
Spark GraphX
- 그래프 처리를 위한 확장 RDD 제공
- Vertex RDD, Edge RDD
- 노드(객체)와 간선(관계)
- 그래프 알고리즘과 그래프 빌더 포함
- 소셜 모델링, PageRank 등
- GraphFrame(Spark2)
- 기존의 GraphX를 확장한 개념
- DataFrame API 제공
- 현재는 외부 패키지 개념으로 별도로 불러와야 함
SparkR
- R언어 Spark 라이브러리 공식 지원
- PySpark와 유사한 API 구조
- dplyr 형식의 데이터 처리 방식 지원
- R에서 Spark가 제공하는 라이브러리를 사용하기 위한 패키지
Spark Interface 
Spark Shell
-
대화형 에디터로 Scala와 Python언어 지원
-
PySpark Shell
- (Spark 설치 경로)/bin/pyspark
Spark Web UI
-
Spark Shell 또는 에디터를 실행한 상태에서 접속 가능
-
Spark app. 정보를 요약해서 보여줌
- Jobs
- 작업 상황과 진행 단계, 태스크 등에 관한 수치를 보여 주며, 작업의 성능을 보기 위해 쓰임
- Storage
- 캐싱된 RDD 정보(캐시 데이터 비율, 용량 등) 확인
- Executors
- 익스큐터 목록과 각 익스큐터 정보 파악. app.이 자원을 효율적으로 사용하고 있는 지 파악 가능
- Environment
- Spark 설정 디버깅
- Streaming
- 스트리밍 app.이 무엇을 수행하는지 볼 수 있음
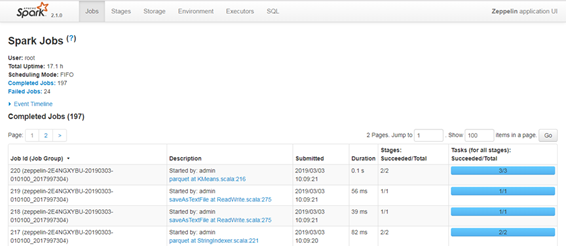
- Jobs
Zeppelin Notebook
- apache 재단에서 후원하는, 인터랙티브 웹 에디터
- jupyter notebook와 유사한 UI
- 다양한 프로그래밍 언어와 인터페이스 지원
- 언어 섞어서 개발 가능
- 다른 기술 셋도 같은 웹에서 다룰 수 있음
- 효율적인 시각화 툴
댓글남기기