Hbase Schema Design
업데이트:
Introduction to Basic Schema Design by Amandeep Khurana 를 보고 정리한 글입니다.
용어 정리
- Table : Hbase는 테이블로 데이터를 조직한다. 테이블 이름은 문자열이고 파일 시스템에서 안전하게 쓰일 수 있는 문자 조합이다.
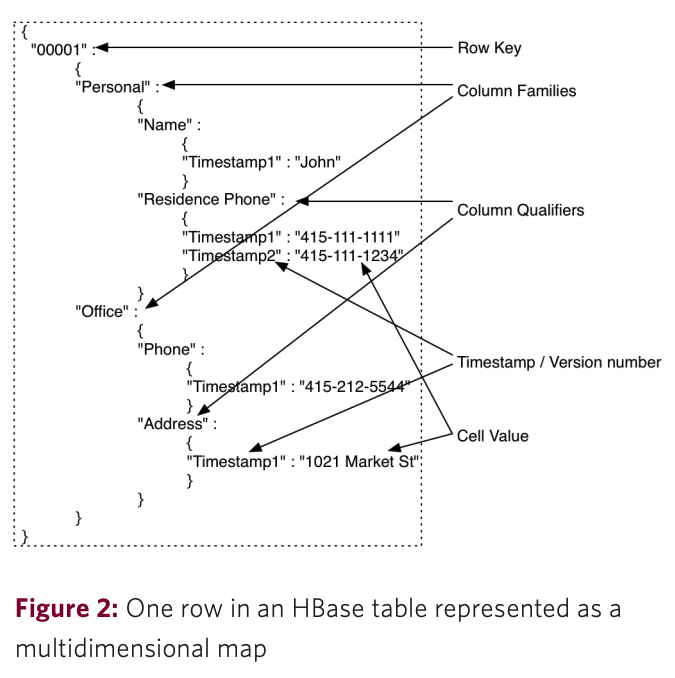
- Row : 테이블 내에서 데이터는 row에 따라 저장된다. Row는 row key 로 유니크하게 식별된다. Row key는 데이터 타입이 없으며 언제나 byte array(
byte[]) 로 다뤄진다. - Column Family : row 내의 데이터는 column family로 그룹된다. column family는 또한 Hbase에서의 물리적인 데이터 저장에도 영향을 준다. 이러한 이유로, column family는 미리 정의해야 하며 쉽게 수정할 수 없다. row가 모든 family에 데이터를 저장할 필요가 없음에도 불구하고, 테이블 내 모든 row는 같은 column family를 가진다. column family는 문자열이고 파일 시스템에서 안전하게 쓰일 수 있는 문자 조합이다.
- Column Qualifier : Column Family 내 데이터는 column qualifier에 의해 어드레싱된다. Column Qualifier는 미리 명세될 필요가 없다. Column Qualifer는 각각에 행에 대해 일관되지 않아도 된다. Row key 처럼 column qualifier는 데이터 타입이 없으며 언제나 byte array로 다뤄진다.
- Cell : row key, column family, column qualifier의 조합은 cell을 유일하게 식별한다. cell 내에 저장된 데이터는 cell의 value라고 불린다. Value 또한 데이터 타입이 없고 byte array로 다뤄진다.
- TimeStamp : cell 내 value들은 버전화된다. Version은 version number(디폴트로는 cell이 쓰인 timestamp)로 식별된다. write시 timestamp가 명세되지 않으면, 현재 timestamp가 사용된다. read시 timestamp 가 명세되지 않으면, 최근의 timestamp를 반환한다. cell value version의 수는 각 column family에 대해 구성된다. 디폴트 버전 수는 3개다.
구조
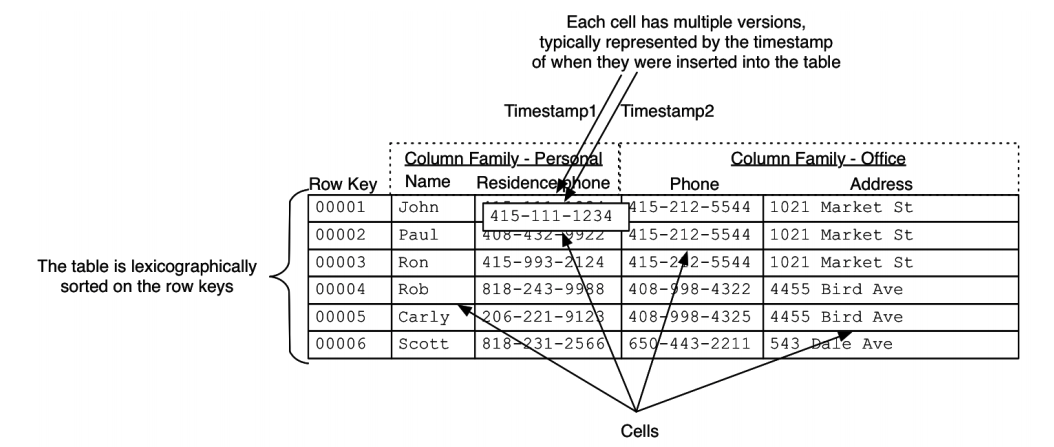
Hbase API는 크게 세 메서드가 있다 : Get, Put, Scan
- GET / PUT : 특정 row를 가져오는 연산, rowkey가 제공되어야 한다
- SCAN : row의 범위로 수행된다. rowkey의 start와 stop을 제공하거나 start, stop이 없을 땐 전체 테이블을 스캔한다.
Hbase는 전형적인 패턴으로 최적화되있고, 디폴트로 가장 최근 버전만을 반환한다. 쿼리로 여러 버전을 요청할 수 있다.
rowkey는 RDB의 primary key와 같다. 그러나, 테이블이 설정된 후에는 컬럼을 rowkey로 변경할 수 없다.
Hbase는 key-value store와 같다.

테이블 설계 기본
Hbase 테이블 설계는 다음 질문에 답하는 것으로 정의될 수 있다.
- rowkey 구조는 어때야 하며 무엇을 담고 있어야 할까?
- table에 몇 개의 column family가 있어야 할까?
- Column family에는 어떤 데이터가 들어가야 할까?
- column family에는 몇 개의 column (qualifier) 이 있어야 할까?
- column의 이름은 뭐가 좋을까? Table 생성 시에 column 이름은 필요 없지만, 읽거나 쓸 때 이름을 알아야 한다
- cell에는 어떤 데이터가 들어가야 할까?
- 각 cell에는 몇 개의 version이 있어야 할까?
Rowkey 설계
가장 중요한 건 rowkey의 구조다. 효율성을 위해서는 접근 패턴(읽기와 쓰기에서) 을 미리 정의하는 것이 중요하다.
스키마를 정의하기 위해 Hbase 테이블에 대한 몇 가지 속성을 고려해야 한다.
-
인덱싱은 Key를 기반으로만 이루어져야 한다
-
테이블은 rowkey를 기반으로 정렬되어 저장된다.
테이블의 각 region은 rowkey의 일부 공간을 담당하며, start와 end rowkey에 의해 식별된다. Region은 start key에서 end key까지 정렬된 rowkey 리스트를 가진다.
-
Hbase Table의 모든 것은
byte[]로 저장된다. 타입은 없다. -
원자성은 row 수준에서만 보장된다. 즉, multi-row 트랜잭션은 보장하지 않는다
-
Column family는 테이블 생성 시 정의되어야 한다
-
Column Qualifier는 동적이고 write할 때 정의된다.
byte[]로 저장되기 때문에 데이터를 넣을 수도 있다.
트위터 팔로우-팔로워 관계 설계 예제는 레퍼런스 참조!
Column family와 column qualifier 이름은 짧게 유지하는 것이 좋다
- key-value 객체가 작아져서 클라이언트로의 네트워크 전송 데이터가 줄어든다
요약
- Rowkey는 설계에 있어 가장 중요하다. 성능에 큰 영향을 미친다.
- Hbase table에서 모든 것은
byte[]로 저장할 수 있어 유연하다. - 유사한 접근 패턴을 가지는 모든 것들은 같은 column family에 저장해라.
- 인덱싱은 오직 Key로만 해야 한다.
- tall table은 잠재적으로 빠르고 단순한 연산을 이끌어내지만, 원자성을 잃게 된다.
- wide table (각 row에 컬럼이 많은 경우) 는 row 수준의 원자성을 상승시킨다.
- 여러 API 호출이 아닌 단일 API 호출로 접근 패턴을 달성할 수 있는지 고려하라
- Hbase는 row간 트랜잭션이 없다. 그리고 당신은 그 로직을 클라이언트 코드에서 작성하길 원하지 않는다.
- 해싱을 통해 고정 길이 키를 만들 수 있다.
- 또한 분산이 높아진다.
- key로 문자열을 사용하지 않으므로 문자열 정렬 특성을 잃게 된다.
- Column Qualifier는 데이터를 저장하는 방식으로 쓰일 수 있다. cell처럼!
- Column Qualifier는 데이터이므로 길이가 스토리지 공간에 영향을 준다. 간결하게 하자.
- 접근 시 디스크 및 네트워크 I/O 비용에도 영향을 준다.
- Column Family 이름의 길이는 key-value 객체로 클라이언트에게 전송되는 데이터 사이즈에 영향을 준다.
- 간결하게!
Reference
Introduction to Basic Schema Design by Amandeep Khurana
댓글남기기