조인 알고리듬의 구현
업데이트:
단일 머신 조인 알고리즘
Nested Loop Join
for each tuple r in R do begin
for each tuple s in S do begin
if r and s satisfy the join condition
output the tuple <r, s>
end
end
- 인덱스를 필요로 하지 않는다.
- 동등 조인이 아닌 경우에도 사용 가능하다.
- 시간 복잡도는 $O(n^2)$이다.
Sort-Merge Join
do {
if (!mark) {
while (r < s) { advance r }
while (r > s) { advance s }
// mark start of "block" of s
mark = s
}
if (r == s) {
result = <r, s>
advance s
return result
}
else {
reset s to mark
advance r
mark = NULL
}
}
- 조인 컬럼으로 정렬되어 있어야 한다.
- 정렬되어 있다면 시간 복잡도는 $O(n)$이다.
- 투 포인터 알고리즘과 유사하다.
- 동등 조인만 가능하다.
Hash Join
for each tuple s in S do begin
insert s into hash table H
end
for each tuple r in R do begin
if there is a tuple s in H that matches hash(r) then
output the tuple <r, s>
end
- 동등 조인만 가능하다.
- S를 build input이라 하고 R을 probe input이라 한다.
- 크기가 작은 테이블을 build input으로 사용하는 것이 좋다.
- 해시 테이블은 메모리보다 작아야 하기 때문이다.
- 시간 복잡도는 $O(n)$이다.
해시 조인은 sort-merge 조인보다 더 효율적이지만 메모리를 더 많이 사용한다.
병렬 조인 알고리즘
Parallel Hash Join
단일 머신 해시 조인을 병렬로 수행.
- hash partitioning
- S, R 이 여러 파티션으로 나뉘어지고 해시하여 동일한 키를 가진 레코드는 한 노드로 모인다.
- shuffle 발생
- build - local hash table build
- 로컬에서 해시테이블 build 한다. - 병렬처리 가능.
- probe
- probe가 수행되려면 build 단계가 완료되어야 한다. (즉 pipeline-break.)
- 로컬에서 수행된다. - 병렬처리 가능.

Parallel Sort-Merge Join
- range partitioning - sort
- S, R을 조인 키의 범위로 파티셔닝한다. 동일한 키를 가진 레코드는 한 노드로 모인다. - shuffle 발생
- data skew가 발생할 수 있다. 이는 샘플링을 통해 해결할 수 있다.
- merge
- 로컬에서 수행된다. - 병렬처리 가능.
Broadcast Join
- 작은 테이블을 모든 노드로 복제(broadcast)하여 조인을 수행.
- 각 노드에서 로컬 조인을 수행. - 병렬처리 가능.
- 작은 테이블이 노드 메모리에 올라갈 수 있을 때 사용.
- 어떤 조인 알고리즘이든 사용 가능하다.
- 큰 테이블은 다른 노드로 전달되지 않아도 되기 때문에 네트워크 비용이 절감된다.
분산 쿼리엔진 사용사례
- spark 2.3 버전부터는 sort-merge join을 선호한다.
- 메모리 안정성을 높게 평가한 것으로 보인다.
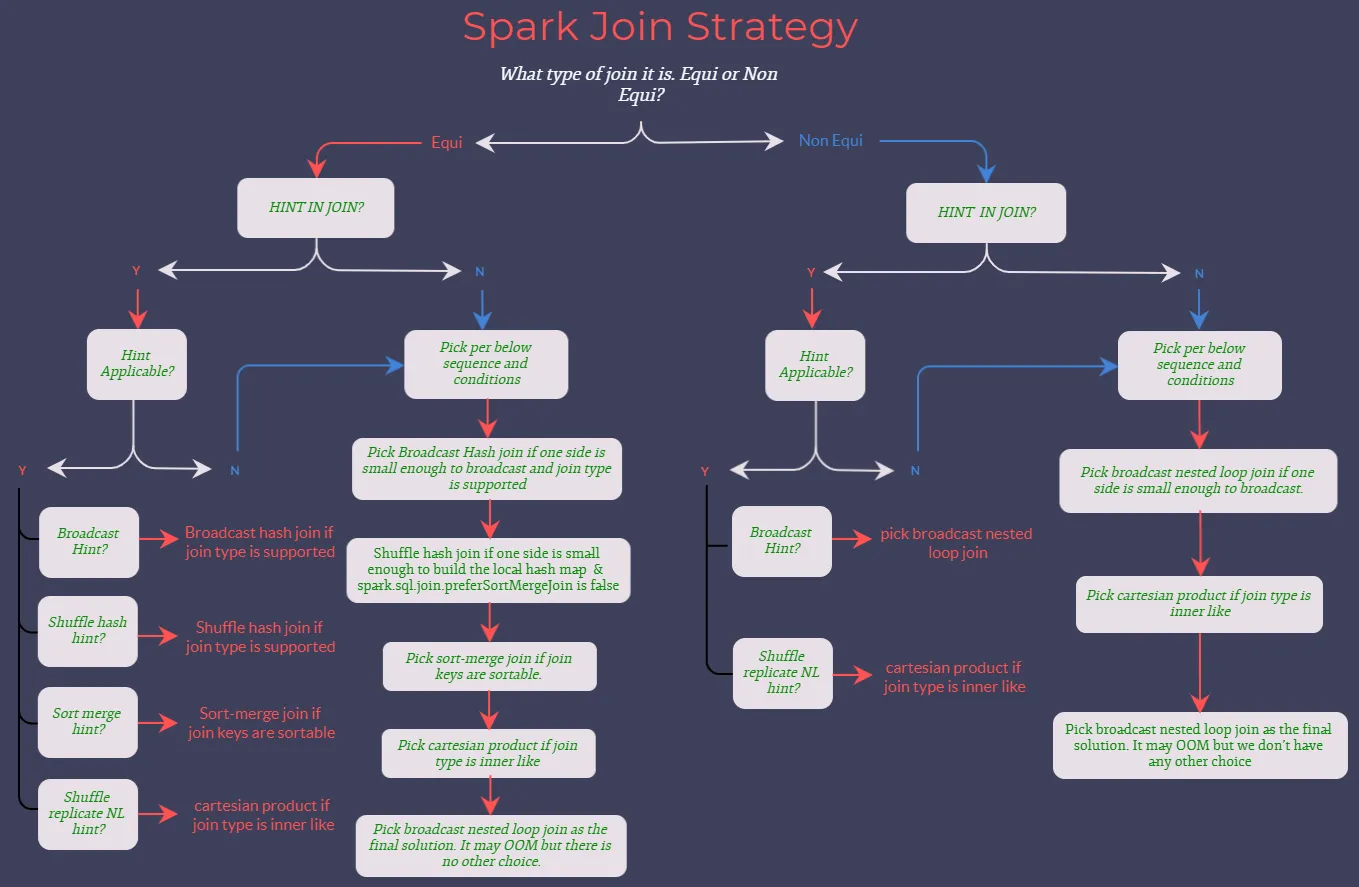
- trino / presto에서는 hash join을 선호한다. sort-merge 조인이 미구현되어 있다.
- datafusion은 hash join을 선호한다.
전반적으로 노드 메모리에 가까운 데이터를 조인하는 경우 sort-merge join이 빠르고, 그렇지 않은 경우 hash join이 빠르다고 한다.
참고
- Database System Concepts, 7th Edition. Abraham Silberschatz, Henry F. Korth, S. Sudarshan. McGraw-Hill Education. 2019.
- CS186 berkely lecture
- https://blog.clairvoyantsoft.com/apache-spark-join-strategies-e4ebc7624b06
댓글남기기