Dremel 논문
업데이트:
논문 Dremel: Interactive Analysis of Web-Scale Datasets
Abstract
- 확장 가능한 대화형 애드혹 쿼리 시스템.
- 읽기 전용 데이터를 분석하는데 쓰인다.
- 다계층 실행 트리와 컬럼 기반 데이터 레이아웃을 결합한다.
- 1조개 행 집계 쿼리를 수초 내 실행 가능
- 수천개 CPU와 페타바이트 급 데이터로 확장 가능
- 맵리듀스 기반 연산을 보완했다.
Introduction
- Dremel은 MapReduce의 완전한 대안은 아니다.
- Dremel은 웹 검색과 병렬 DBMS 아이디어를 기반으로 한다.
- 1.아키텍처는 분산 검색 엔진의 서빙 트리 개념을 차용한다. 쿼리는 트리에서 푸시 다운되며 각 단계별로 재작성된다. 쿼리의 결과는 트리의 저수준에서 받은 응답을 집계하여 구성된다.
- 2.애드혹 쿼리를 위한 고수준 SQL-like 언어를 제공한다. Hive나 Pig와는 다르게 MR job으로 변환하지 않고 native하게 실행한다.
- 3.컬럼 기반 저장 표현을 사용한다. 이는 보조 저장장치로부터 더 적은 데이터를 읽을 수 있게 하고, 효율적인 압축으로 CPU를 적게 사용한다.
- 논문에서 소개할 것들
- 1.중첩된 데이터에 대한 새로운 컬럼 기반 저장 형식. 그리고 중첩 레코드를 컬럼으로 분해하고 조립하는 알고리즘
- 2.Dremel의 쿼리 언어와 실행에 대한 개괄. 컬럼 기반의 중첩 데이터에서 효과적으로 수행하도록 설계됨.
- 3.웹 검색에서 사용되는 실행 트리가 데이터베이스 처리에 어떻게 적용되는지. 집계 쿼리를 효율적으로 수행하는 데 있어 어떤 도움이 되는지.
- 4.1조 레코드, 수 테라바이트 데이터셋에 대한 1000~4000개 노드에서의 실험.
Data Model
Protocol Buffers라 불리는 데이터 모델은 강타입 중첩 레코드 구조이다.
\(τ = dom | ⟨A1 : τ[∗|?],...,An : τ[∗|?]⟩\)
- $τ$는 원자 또는 레코드 타입을 나타낸다.
- 원자 타입은 정수, 부동소수점 문자열 등을 나타낸다.
- 레코드 타입은 1개 이상의 필드를 가진다. $*$는 여러 레코드가 올 수 있음을 나타내고, $?$는 필드가 없을 수 있음을 나타낸다.
예시

copilot. dremel encoding vs parquet?
Origin and Usage: Dremel encoding was developed by Google for use in their Dremel system, which is used for interactive analysis of large datasets. Parquet, on the other hand, was developed by Twitter and Cloudera for use in the Hadoop ecosystem, and is often used with tools like Apache Spark and Apache Hive.
Data Model: Both Dremel and Parquet support nested data structures. However, Dremel uses a model based on Protocol Buffers, ~~while Parquet uses a model based on Apache Avro. ~~
Encoding and Compression: Both Dremel and Parquet support a variety of encoding and compression techniques. However, Parquet is often praised for its efficient use of encoding and compression to reduce storage space and increase query performance.
Compatibility: Dremel encoding is primarily used within Google’s ecosystem. Parquet, being an open-source project, has wider compatibility with various big data processing tools in the Hadoop ecosystem.
Nested Columnar Storage
주어진 필드의 모든 값을 연속적으로 저장하여 접근 효율을 높여야 한다.
Repetition and Definition Levels
값만 가지고는 레코드의 구조를 전달할 수 없다. 컬럼 기반의 레코드 구조에서 무손실 표현을 위해 필요하다.
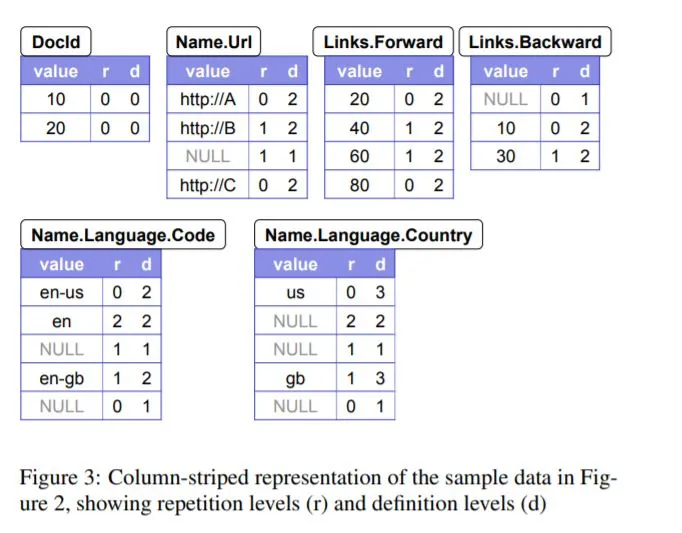
반복 수준
- 값은 반복될 수 있다. (figure 2 r1 참고).
- 반복 수준 : 반복된 값 중에서, 어떤 필드의 값인지를 알려준다.
정의 수준
- 얼마나 많은 필드가 정의되지 않을 수 있는지(optional 혹은 repeated 때문에) 를 알려준다.
인코딩
- 각 컬럼은 블록의 집합으로 저장된다.
- 각 블록은 반복과 정의 수준을 포함한다.
- 그리고 압축된 필드값을 가진다.
이해가 잘 안된다… 잘 정리된 글 Dremel Encoding
Splitting Records into Columns
repetition과 definition을 계산하는 알고리즘
- 레코드를 순회하면서 각 필드값의 레벨을 계산한다.
- 필드값이 없더라도 계산되어야 한다. 희소한 데이터가 많기 때문에 가능한 가볍게 계산되어야 한다.
- column stripe를 생성하기 위해 field writers 트리를 생성한다.
Record Assembly
- 컬럼 기반 데이터로부터 레코드를 구성하는 것은 MR과 같은 레코드 기반 데이터 처리 도구에서 중요하다.
- 필드의 집합이 주어지면 선택된 필드만 가져와서 레코드를 구성한다.
- 유한 상태 기계(FSM)를 생성한다.
- 각 필드에서 필드값과 레벨을 읽고 출력 레코드에 값을 순차적으로 더한다
- FSM 상태는 각 선택된 필드의 reader와 연관된다.
- 상태 변경은 반복 레벨로 레이블링된다.
- reader가 값을 가져오면 다음 반복 레벨을 참고해 다음 reader를 결정한다.
어렵다… 나중에 다시 읽어보자.
Query Language
- Dremel의 쿼리 언어는 SQL에 기반하며 컬럼 기반 중첩 저장 구조에 효율적으로 구현되도록 설계되었다.
- 각 SQL문은 입력으로 한 개 이상의 중첩 테이블과 스키마를 받아서 중첩 테이블과 출력 스키마를 생성한다.
Query Execution
- 코어 아이디어는 읽기-전용 시스템 맥락에 있다.
Tree Architecture
- Dremel은 쿼리 실행을 위해 멀티 레벨 서빙 트리를 사용한다.
- 루트 서버는 쿼리를 받고 테이블의 메타데이터를 읽고 서빙 트리의 다음 레벨로 쿼리를 전달한다.
- 리프 서버는 저장 레벨 혹은 로컬 디스크의 데이터 접근과 통신한다.
- 루트 서버는
SELECT A, COUNT(B) FROM T GROUP BY A쿼리를 받아 재작성한다.SELECT A, SUM(c) FROM (R1 UNION ALL ... Rn) GROUP BY A - 서빙 트리의 말단 서버가 수행하는 쿼리는
Ri = SELECT A, COUNT(B) AS c FROM Ti GROUP BY A.Ti는 테이블의 파티션이다. - 각 말단 서버의 결과를 중간 서버가 집계하여 완료된다. 이러한 트리는 쿼리의 병렬 실행을 가능하게 한다.
Query Dispatcher
- Dremel은 멀티 유저 시스템이다. 즉, 여러쿼리가 동시에 실행된다. 쿼리 디스패처는 쿼리의 우선순위와 부하 균형에 기반하여 스케줄링한다. 한 서버가 느려질 때를 위한 내고장성을 제공하기도 한다.
- 각 쿼리의 데이터가 처리 유닛보다 클 때도 있다. 처리 유닛을 슬롯이라 하며, 슬롯은 리프 서버의 실행 스레드이다. 쿼리 디스패처는 태블릿(파티션)의 처리 시간 히스토그램을 계산한다. 처리 시간이 불균형하다면 다른 서버에 다시 스케줄링한다.
- 리프 서버는 중첩 데이터의 스트라이프를 컬럼 표현으로 읽는다. 스트라이프의 각 블록은 비동기적으로 prefetch된다. 태블릿은 보동 3개로 복제된다. 리프 서버가 태블릿 복제에 접근하지 못하면 다른 복제본에 접근한다.
- 각 서버는 내부 실행 트리를 가진다. 내부 트리는 물리 쿼리 실행 계획과 대응된다.
- project-select-aggregate 쿼리의 실행 계획은 입력 컬럼을 스캔하고 집계 결과를 방출하는 반복자의 집합이다.
Experiment 생략
Observations
Dremel은 한달에 수조 개의 레코드를 스캔한다.
- 대부분의 쿼리는 10초 이내로 수행된다.
- 선형에 가까운 확장성을 보인다.
- MR또한 컬럼 기반 스토리지에서 이점을 보인다.
- 레코드 구성과 파싱은 비싸다. 소프트웨어 수준(쿼리 처리 수준을 넘어)에서 직접 컬럼 기반 데이터를 사용하도록 최적화해야 한다.
- MR과 쿼리 처리는 상호 보완할 수 있다. 하나의 출력이 다른 입력으로 사용될 수 있다.
- 쿼리의 속도와 정확도가 조정 가능하다면 쿼리는 대부분의 데이터를 보는 대신 빨리 종료될 수 있다.
Conclusions
대규모 데이터셋의 대화형 분석 분산 시스템인 Dremel을 소개했다. 이는 MR 패러다임을 보완한다. 수조 개 수 테라바이트의 성능을 논의했으며 저장 형태, 쿼리 언어 실행 등의 주요 방법을 살펴보았다. 미래에는 일반적인 대수 연산, 조인 확장 매커니즘을 보완할 계획이다.
댓글남기기