Presto 논문
업데이트:
Abstract
Presto는 Facebook 내 SQL 분석 워크로드 대부분을 지원하는 분산 쿼리 엔진이다. Presto의 커넥터 API는 고성능 입출력 인터페이스를 제공하기 위한 플러그인을 허용한다. 하둡 데이터 웨어하우스, RDBMS, NoSQL, 스트림 처리 시스템 등이 플러그인에 포함된다. 이 논문에서는 Facebook에서 Presto 가 지원하는 유즈케이스를 먼저 소개하고 아키텍처와 구현을 설명한다. 이후 유즈케이스를 위한 특징과 성능 최적화를 소개한다. 마지막으로 성능 결과를 소개한다.
Introduction
빅데이터에서 빠르고 쉽게 인사이트를 추출하는 능력은 점점 중요해진다. 큰 데이터를 수집하고 저장하는 것이 싸지면서, 빠르고 쉬운 쿼리는 더 중요해졌다. SQL과 같은 쿼리 언어를 사용하면 조직 내 많은 사람들의 데이터 분석 접근성을 좋게 한다. 그러나 조직 내 호환되지 않는 여러 SQL-like 시스템을 사용하면 사용성은 떨어진다.
Presto는 2013년에 Facebook에서 만들었다. AWS Athena또한 Presto로 만들어졌다.
Presto는 ANSI SQL을 지원한다. 하둡, RDBMS, NoSQL 시스템, Kafka와 같은 스트리밍 시스템에 쿼리할 수 있다. ‘Generic RPC’ 커넥터를 활용하면 쉽게 SQL 인터페이스를 추가할 수 있다. Presto는 HTTP API, JDBC 를 지원하며 업계 표준 BI도구와 호환된다. 내장 하이브 커넥터는 HDFS/S3 와 같은 분산 파일 시스템에 네이티브하게 읽고 쓸 수 있다. ORC, Parquet, Avro와 같은 파일 포맷도 지원한다.
Presto는 대화형/BI 쿼리와 장시간 배치 ETL잡을 수행하고 A/B 테스팅에도 사용된다. 매일 Facebook의 수백 페타바이트 데이터와 수 조 행을 처리한다.
Presto 특징
- 멀티 테넌트. 수백 개의 메모리, 입출력, CPU 집약적 쿼리를 수행한다. 클러스터 리소스를 활용하면서 수천 개의 워커 노드로 확장된다.
- 확장성. 하나의 쿼리로 여러 데이터 소스를 처리할 수 있다. 여러 시스템을 통합하는 복잡성을 줄인다.
- 유연성. 다양한 유스케이스를 지원한다.
- 고성능. 코드 생성을 포함한 여러 기능과 최적화가 가능하다. 여러 쿼리는 워커 노드 내 하나의 long-lived JVM 프로세스를 공유한다. 이는 응답 시간을 줄이지만 통합된 스케줄링, 리소스 관리와 고립성을 요구한다.
Use Cases
Interactive Analytics
페이스북은 대량의 멀티테넌트 데이터 웨어하우스를 운영중이다. 비즈니스 함수와 조직은 클러스터를 공유한다. 데이터는 분산 파일시스템에 저장되고 메타데이터는 별도 서비스에 저장된다. 이러한 시스템은 HDFS, Hive metastore service와 유사한 API를 가진다. 이를 ‘Facebook Data warehouse’라 부르며 Presto의 Hive 커넥터 변형을 이용해 읽고 쓴다.
엔지니어와 데이터 사이언티스트들은 가설 검증, 시각화 혹은 대시보딩을 위해 적은 양의 데이터(~50GB-3TB compressed)를 주로 수행한다. 유저는 주로 쿼리 작성 도구, BI도구, Jupyter notebook를 사용한다. 각 클러스터는 다양한 형태의 50~100개 쿼리를 동시 수행하며 수초/분 내 결과를 반환해야 한다. 유저는 수행 시간에 예민하며 쿼리 자원 요구사항에 관심이 없다. 유저는 탐색 분석 대부분에서 전체 결과 반환을 요구하지 않는다. 쿼리는 최초 결과 반환 후 취소되거나 LIMIT 절을 사용하여 반환 데이터를 제한한다.
Batch ETL
새로운 데이터는 일정 간격의 ETL쿼리를 수행함으로써 데이터 웨어하우스에 적재된다. 쿼리는 task들의 의존성을 결정하고 적절하게 스케줄링하는 워크플로 관리 시스템에 의해 스케줄링된다. Presto는 레거시 배치 처리 시스템으로부터의 이전을 지원한다. 또한 ETL쿼리는 CPU의 많은 부분을 차지한다. 이러한 쿼리들은 데이터 엔지니어에 의해 작성되고 최적화된다. ETL 쿼리들은 대화형 분석 쿼리보다 리소스를 많이 사용한다. 또한 CPU 집약적인 변환과 메모리 집약적 집계 혹은 조인을 사용한다. 쿼리 지연은 리소스 효율성과 클러스터 처리량보다 상대적으로 덜 중요하다.
A/B Testing
A/B 테스팅은 통계적 가설 검증을 통한 제품 변경의 임팩트를 평가하는 것이다. Facebook 내 대부분의 A/B 테스트 인프라는 Presto에서 수행된다. 유저들은 테스트 결과가 몇 시간 내 제공되며 정확하기를 기대한다. 또한 유저가 통찰력을 얻기 위해 대화형 대기 시간(∼5-30초) 내에서 결과에 대해 임의의 slice와 dice를 수행할 수 있어야 한다. 미리 집계하는 방식으로 요구사항을 충족하는 것은 어렵다. 때문에 결과는 즉시 계산되어야 한다. 연산은 여러 데이터 셋을 조인해야 한다. 쿼리는 작아야 한다.
Developer / Advertiser Analytics
외부 개발자나 광고주를 위한 리포팅 도구는 Presto를 사용한다. Facebook Analytics 는 Facebook 플랫폼을 사용하여 애플리케이션을 개발하는 개발자를 위한 분석 도구이다. 이는 제한된 쿼리 집합을 사용하여 웹 인터페이스를 노출한다. 집계 데이터 크기는 크지만 쿼리는 매우 선택적이다. 유저가 그들의 앱과 광고에만 접근하기 때문이다. 대부분의 쿼리는 조인, 집계, 윈도우 함수를 포함한다. 데이터 수집 지연 시간은 수분이며 쿼리 지연시간은 수초 내로 매우 제한적이다. 99.999% 가용해야 하며 많은 유저의 수백개 동시 쿼리를 지원해야 한다.
- 배치 ETL에도 쓰는군.
- 유즈케이스가 우리 회사 상황과 비슷하군.
Architecture Overview
Presto 클러스터는 단일 코디네이터 노드와 하나 이상의 워커 노드로 구성된다.
- 코디네이터는 쿼리를 받아서 파싱하고 계획하고 최적화한다. 또한 쿼리간 조정을 담당한다.
- 워커 노드는 쿼리를 처리한다.
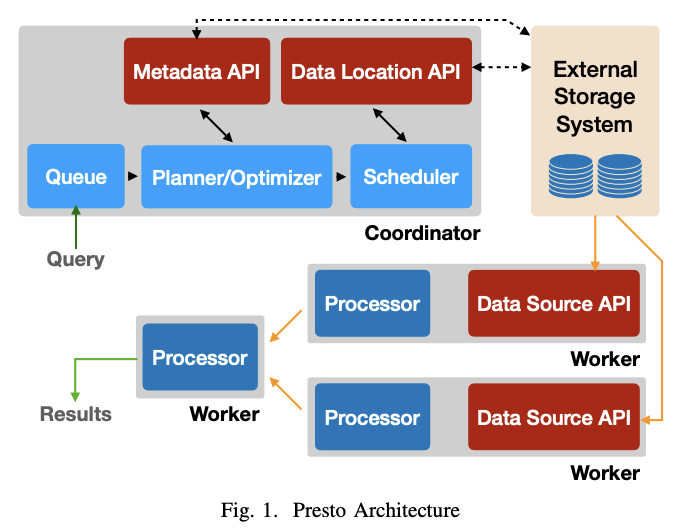
- 클라이언트는 코디네이터에게 SQL 구문을 담은 HTTP 요청을 보낸다.
- 코디네이터는 쿼리 정책 평가, SQL파싱 및 분석, 분산 실행 계획을 생성 및 최적화하여 요청을 처리한다.
- 코디네이터는 계획을 워커에게 분배하고 task의 수행을 시작한다. 그리고 외부 저장소에 있는 데이터 청크를 처리하는 splits를 나열한다. splits는 task에 할당된다.
- 워커 노드는 task를 실행한다. task는 splits를 처리해 외부 저장소에서 데이터를 가져오거나, 다른 워커에서 생성한 중간 결과를 처리한다.
- 워커는 많은 쿼리를 동시에 처리한다.
- task 실행은 가능한 파이프라이닝되고 데이터는 사용 가능하지면 task간 전달된다.
- 특정 쿼리에서는 모든 데이터가 처리되기 전 결과를 반환할 수 있다.
- 중간 데이터와 상태는 가능한 인메모리에 저장된다.
- 노드 간 데이터 셔플될 때는 지연을 줄이기 위해 버퍼가 조정된다.
Presto는 다양한 플러그인 인터페이스를 제공한다. 플러그인은 커스텀 데이터 타입, 함수, 접근 제어, 이벤트 컨슈머, 쿼리 정책, 설정 프로퍼티를 제공한다.
또한 presto가 외부 데이터 저장소와 통신할 수 있는 connectors를 제공한다.
- Connector API는 메타데이터 API, 데이터 위치 API, 데이터 소스 API, 데이터 싱크 API 4가지로 구성된다.
- API는 물리적으로 분산된 실행 엔진 환경에서 효율적인 구현을 허용하도록 설계되었다.
System Design
A. SQL Dialect
Presto는 ANSI SQL 명세를 따른다. 명세의 모든 기능을 구현한 것은 아니지만 구현된 기능은 가능한 명세를 지원한다. 사용성을 위한 적은 확장만 추가로 만들어져 있다. 예를 들어 ANSI SQL에서 맵과 배열 타입과 같은 복잡한 타입의 연산은 까다롭다. 이를 단순화하기 위해 익명 함수와 내장 고차 함수(transform, filter, reduce)를 지원한다.
B. Client Interfaces, Parsing, and Planning
- 클라이언트 인터페이스 : 코디네이터는 주로 RESTful HTTP 인터페이스를 노출하고 CLI도 지원한다. 다양한 BI도구와 호환되는 JDBC 드라이버도 지원한다.
- 파싱 : SQL문을 구문 트리로 변환하기 위해 ANTLR 기반의 파서를 사용한다. 분석기는 타입 결정, 변환, 함수 해석, 스코프, 서브쿼리, 집계, 윈도우 등을 결정하기 위해 트리를 사용한다.
- 논리 계획 : 논리 플래너는 구문 트리와 분석 정보를 이용해서 plan node의 트리 형태로 인코딩된 중간 표현(IR)을 생성한다. 각 노드는 물리적 논리적 연산을 나타낸다. 계획 노드의 자식은 입력값이다. 플래너는 논리적인 노드를 생성한다. 어떻게 계획이 실행될 지에 대한 정보는 갖지 않는다.

C. Query Optimization
논리 계획을 효율적인 실행 전략을 가진 물리적인 구조로 변환한다. 특정 지점에 도달하기까지 greedy하게 변환 규칙 집합을 평가한다. presto는 predicate, limit 푸시다운, column pruning, decorrelation 등의 룰을 가진다. 테이블과 컬럼 통계를 사용해 조인 전략 선택, 조인 재정렬 등 비용 기반의 최적화도 한다.
- Data Layouts : 옵티마이저는 커넥터 Data Layout API를 통해 데이터의 물리적 layout을 알 수 있다. 커넥터는 위치, 파티셔닝, 정렬, 그룹핑, 인덱스 등 데이터 속성을 알려준다. 단일 테이블에서 다른 속성을 가진 여러 layout을 반환할 수 있다. 옵티마이저는 최적의 layout을 선택한다.
- Predicate Pushdown : 옵티마이저는 range와 equality predicate을 커넥터에게 전달하여 데이터를 효과적으로 필터링할 수 있다. MySQL 커넥터는 데이터가 존재하는 샤드만 조회한다. 여러 레이아웃이 있다면 predicate 컬럼에 인덱싱된 레이아웃을 선택한다. 하이브 커넥터는 partition pruning 및 파일 포맷 특징을 활용해서 성능 향상한다.
- Inter-node Parallelism : 계획에서 워커간 병렬 수행될 부분(stage)를 식별한다. stage는 하나 이상으로 분산된다. 각각 다른 집합의 입력 데이터에서 동일한 계산을 수행한다. 엔진은 버퍼된 인메모리 데이터 전송(shuffle)을 통해 stage간 데이터를 전달한다. 셔플은 지연시간, 버퍼 메모리, 높은 CPU 오버헤드를 추가한다. 때문에 옵티마이저는 총 셔플 수를 신중하게 추론한다.
- Intra-node Parallelism : 옵티마이저는 단일 노드에서 스레드로 병렬화할수 있는 부분을 식별한다. 이전시간 오버헤드와 상태(해시테이블 등) 이 효율적으로 스레드 간 공유될 수 있기에 노드간 병렬화보다 노드내 병렬화가 더 효율적이다. 엔진은 단일 파이프라인을 여러 스레드에서 수행할 수있다.


D. Scheduling
코디네이터는 계획 stage를 실행 가능한 task의 형태로 워커에게 분산한다.task는 단일 처리 단위라고 생각할 수 있다. 이후 코디네이터는 한 stage의 task를 다른 stage의 task에 shuffle로 연결한다. 데이터를 사용할 수 있는 즉시 stage간 스트리밍한다.
task는 여러 파이프라인을 가질 수 있다. 파이프라인은 operators의 연결로 구성된다. 각 오퍼레이터는 데이터에 대한 단일 연산을 수행한다. 예를 들어 해시 조인을 수행하는 태스크는 적어도 두 파이프라인으로 구성되야 한다.
- 해시 테이블을 생성하는 build 파이프라인
- probe 측에서 데이터를 전송하고 조인을 수행하는 probe 파이프라인
The classic hash join algorithm for an inner join of two relations proceeds as follows:
First, prepare a hash table using the contents of one relation, ideally whichever one is smaller after applying local predicates. This relation is called the build side of the join. The hash table entries are mappings from the value of the (composite) join attribute to the remaining attributes of that row (whichever ones are needed).
Once the hash table is built, scan the other relation (the probe side). For each row of the probe relation, find the relevant rows from the build relation by looking in the hash table.
옵티마이저는 각 파이프라인을 분할하여 독립적으로 수행하도록 병렬화할 수 있다. 위쪽 그림에서 build 파이프라인을 scan data 파이프라인과 해시 테이블을 생성하는 파이프라인으로 분할한다. 파이프라인들은 로컬 인메모리 셔플을 통해 합쳐진다.
쿼리 수행을 위해 엔진은 두개의 스케줄링 결정 집합을 만든다. 하나는 스테이지가 스케줄될 순서를 결정한다. 다른 하나는 스케줄될 태스크의 수를 결정한다.
- Stage Scheduling : Presto는 두개의 stage 스케줄링 정책을 지원한다.
- all-at-once : 모든 스테이지 수행을 동시에 스케줄링하여 시간을 최소화한다. 데이터는 가용해지자마자 처리된다. 지연시간에 민감한 유즈케이스에 적합하다.(대화형 분석, 개발자 분석, A/B 테스트)
- phased : 데이터 흐름과 연결된 컴포넌트를 모두 식별하고 우선순위에 따라 스케줄링한다. 예를 들어 해시 조인에서 build 파이프라인을 먼저 수행한 뒤 probe 파이프라인을 수행한다. 이 정책은 배치 처리 등에서 메모리 효율적이다.
- Task Scheduling : 태스크 스케줄러는 계획 트리를 검사하고 leaf와 intermediate stage로 분류한다. 단말 스테이지는 커넥터로부터 데이터를 읽는다. 중간 스테이지는 중간 결과를 다른 스테이지로 처리한다.
- leaf stage : 태스크 스케줄러는 네트워크와 커넥터의 제약조건을 고려하여 태스크를 워커 노드에 할당한다. 예를 들어 스케줄러는 커넥터 데이터 레이아웃을 활용하여 소스 데이터가 있는 노드에 task를 할당한다. 대부분의 CPU 시간은 압축해제/디코딩/필터링/변환에 소요된다. 이것들은 병렬화 가능하기에 이러한 스테이지를 가능한 많은 노드에서 수행하면 빠르다. 때문에 말단 스테이지는 대부분의 워커 노드에서 수행되도록 충분한 수의 task로 쪼개진다.
- intermediate stages : 중간 스테이지 태스크들은 모든 워커 노드에 위치할 수 있지만 각 스테이지의 태스크 수는 정해져야 한다. 태스크 수는 커넥터 설정, 계획 속성, 데이터 레이아웃 등에 기반한다. 떄떄로 엔진은 동적으로 태스크 수를 변경한다.
- Split Scheduling : 말단 스테이지의 태스크가 시작하면 워커 노드는 하나 이상의 스플릿을 처리한다. 분산 파일시스템에서 읽을 때 스플릿은 파일 경로와 파일의 리전 오프셋으로 구성된다. 레디스 kv 저장소에서 읽을 때 스플릿은 테이블 정보, 키, 값 형태, 쿼리할 호스트 목록으로 구성된다.
- Split Assignment : 코디네이터는 스플릿을 태스크에 할당한다. Presto는 커넥터에게 스플릿의 작은 배치를 요청하고 task에게 lazy하게 할당한다. 이는 다음과 같은 이점이 있다.
- 쿼리 응답 시간을 커넥터가 스플릿을 읽는 시간과 분리할 수 있다.
- 모든 데이터를 처리하지 않고도 결과를 반환할 수 있다.
LIMIT절을 사용하면 더 빨리 결과를 반환할 수 있다. - 워커는 스플릿의 큐를 유지한다. 코디네이터는 가장 짧은 큐에 태스크를 할당한다. 큐를 작게 유지하면 워커간 성능 차이를 해결할 수 있다.
- 모든 메타데이터를 메모리에 유지하지 않아도 된다.
- 다만 쿼리 진행 상황의 정확한 추정은 어렵다.
- Split Assignment : 코디네이터는 스플릿을 태스크에 할당한다. Presto는 커넥터에게 스플릿의 작은 배치를 요청하고 task에게 lazy하게 할당한다. 이는 다음과 같은 이점이 있다.
E. Query Execution
- Local Data Flow
- 스플릿이 스레드에 할당되면 driver loop로 실행된다. 드라이버는 오퍼레이터 간 데이터 이동을 잘 수행하게 한다.
- 드라이버 루프가 처리하는 데이터의 단위를 page라 한다. 이는 row들의 컬럼 기반 인코딩이다. 커넥터 데이터소스 API는 split을 읽어 page를 반환한다. 오퍼레이터는 입력 페이지를 받아 연산하고 출력 페이지를 반환한다.

- 드라이버 루프는 계속해서 오퍼레이터간 페이지를 전송한다.
- Shuffle
- Presto는 지연시간을 최소화하고 리소스 사용률을 최대화하도록 설계되었다. 노드간 데이터 흐름도 마찬가지다.
- Presto는 중간 결과를 교환하기 위해 인메모리 버퍼된 셔플을 사용한다. 태스크가 생성하는 데이터는 버퍼에 저장되고 다른 워커는 HTTP long-polling을 사용해 데이터를 가져온다. 서버는 클라이언트가 이전 응답의 토큰을 이용해 다음 요청을 보낼때까지 데이터를 유지한다. long-polling 은 응답 시간을 최소화한다.
- 위 매커니즘은 셔플 데이터를 디스크에 저장하는 다른 시스템(spark)보다 적은 지연시간을 제공한다.
- 엔진은 입출력 버퍼의 목표 사용률을 유지하기 위해 병렬도를 조정한다. 꽉 찬 출력 버퍼는 처리를 멈추게 하며 사용률이 낮은 입력 버퍼는 불필요한 처리 오버헤드를 더한다.
- 엔진은 출력 버퍼 사용률이 높으면 스플릿의 수를 줄인다. 이는 네트워크 자원을 공정하게 공유할 수 있게 하고 클라이언트(다른 노드나 엔드 유저)가 데이터에 접근할 수 있게 한다.
- 엔진은 입력 버퍼가 용량을 초과하지 않고 유지되도록 하기 위한 목표 HTTP 요청 동시성을 계산한다. 따라서 버퍼가 채워짐에 따라 HTTP 요청 동시성이 줄어들고 업스트립 태스크는 느려진다.
- Writes
- ETL잡은 다른 테이블에 쓰일 데이터를 생성한다. 원격 스토리지 환경에서는 쓰기 동시성이 중요하다.(커넥터 데이터 싱크 API를 통해 쓰는 스레드 개수)
- 아마존 S3를 스토리지로 사용하는 Hive 커넥터에서 모든 동시 쓰기는 새 파일을 생성한다. 때문에 많은 동시성으로 인한 쓰기는 작은 파일을 생성할 가능성이 높다. 이는 파일 읽기 시 많은 메타데이터 연산과 지연된 읽기 성능으로 인해 오버헤드를 발생시킨다. 그러나 너무 적은 동시성의 쓰기는 처리량이 낮다. Presto는 쓰기 버퍼 임계값을 초과하면 워커 노드에 태스크를 추가하여 동적으로 쓰기 동시성을 증가시킨다.
F. Resource Management
Presto의 자원 관리는 단일 클러스터에서 수백개의 쿼리를 동시 처리할 수 있게 한다. 또한 CPU, IO, 메모리 사용률을 최대화할 수 있다.
- CPU Scheduling
- Presto는 전체 클러스터 처리량을 최적화한다. 로컬 스케줄러는 낮은 처리시간, 쿼리간 공정한 CPU 공유를 최적화한다.
- 태스크의 자원 사용률은 각 스플릿에 주어진 총 thread CPU 시간이다. 조정 오버헤드를 최소화하기 위해 태스크 레벨에서 CPU 사용률을 추적하고 스케줄링을 로컬에서 수행한다.
- Presto는 멀티태스킹 모델을 위해 모든 워커노드에 있는 태스크를 스케줄링한다. 스플릿은 CPU 점유시간 제한이 있다. 제한에 도달하지 않더라도 출력 버퍼가 가득 차거나 입력 버퍼가 비었거나 OOM이 발생하면 로컬 스케줄러는 다른 다스크를 처리한다. 따라서 CPU 사용률은 증가한다.
- 실행할 태스크를 선정할 때는 태스크의 CPU 시간을 5단계로 분리한 멀티 레벨 피드백 큐를 사용한다. split의 입출력과 CPU 특성은 다양해서 공정한 멀티 태스킹을 달성하는 것은 쉽지 않다. 정규표현식과 같은 복잡한 함수는 CPU를 많이 사용하고 어떤 커넥터는 비동기 API를 지원하지 않아 스레드를 점유할 수 있다.
- Memory Management
- Memory Pools
- 유저 메모리는 데이터를 처리하는 데 추론 가능한 메모리 사용량이다. 예를 들어 집계의 메모리 사용량은 카디널리티에 비례한다.
- 시스템 메모리는 구현의 부산물에 해당하는 사용량이다. 예를 들어 셔플 버퍼는 입력 데이터와 관계없다.
- 엔진은 유저와 전체(유저+시스템) 메모리에 별도의 제한을 부여한다. 글로벌(워커간 집계된) 제한 혹은 노드간 제한을 초과하는 쿼리는 kill된다.
- Spilling
- 노드가 OOM되면 엔진은 실행시간의 오름차순으로 적합한 태스크를 취소한다. 취소는 상태를 disk에 spill하는 방식으로 수행된다.
- Presto는 해시 조인과 집계 연산에 스필을 지원한다.
- Reserved Pool
- 노드가 OOM이고 클러스터가 spill하지 않도록 설정되었다면 혹은 취소 가능한 메모리가 남아있지 않다면, 예약 메모리 메커니즘이 수행된다.
- 모든 노드에 쿼리 메모리 풀은 일반 풀과 예약 풀로 나뉜다. 워커 노드의 일반 풀이 고갈되면 워커에서 가장 많은 메모리를 사용하는 쿼리는 모든 워커 노드의 예약 풀로 승진된다.
- 만약 노드의 일반 풀이 고갈되고 예약 풀이 점유되면, 다른 태스크의 모든 메모리 요청은 대기한다.
- 예약 풀을 사용하지 않고 무거운 쿼리를 kill하는 구성도 가능하다.
- Memory Pools
G. Fault Tolerance
- Presto는 저수준 retry를 통해 일시적인 오류 복구가 가능하다.
- 다만 2018말 기준으로 코디네이터 또는 워커 노드의 실패에 대해 의미있는 내장 내결함성을 갖고 있지 않다. 코디네이터가 실패하면 클러스터를 사용할 수 없고 워커 노드가 실패하면 노드 내 수행되는 모든 쿼리가 실패한다.
Query Processing Optimizations
A. Working with the JVM
- Presto는 자바로 구현되었고 Hotspot JVM에서 실행된다.
- 데이터 합축 체크섬 알고리즘 등의 성능에 민감한 코드는 method inlining, loop unrolling 등 JIT 컴파일러 수준의 최적화가 도움이 된다.
- 가비지 컬렉션 알고리즘의 선택은 성능에 극적인 효과를 줄 수 있다. Presto는 G1GC를 사용한다. G1GC는 특정 크기를 초과하는 객체를 잘 다루지 못하기에 Presto는 큰 객체나 버퍼를 할당하는 것을 피하고 필요하면 분할된 배열을 사용한다. 크고 링크가 많은 객체 그래프는 G1의 remembered set 때문에 문제가 된다. 쿼리 실행의 주요 경로에 있는 자료구조는 참조와 객체 카운트를 줄이기 위해 평평한 메모리 배열로 구현되었다. 예를 들어
HISTOGRAM집계는 버킷 키와 카운트를 평평한 배열의 집합과 해시 테이블에 저장하고 각 히스토그램별로 독립적인 객체를 유지하지 않는다.
B. Code Generation
코드 생성은 JVM 바이트코드를 만든다. 이것은 두가지 형태를 가진다.
- Expression Evaluation : 쿼리 엔진의 성능은 복잡한 표현을 평가하는 데 달려 있다. Presto는 표현 해석기를 포함하지만 상용에서 사용하기에는 느리다. 때문에 Presto는 상수, 함수 호출, 변수 참조 등를 네이티브하게 다루는 바이트코드를 생성한다.
- Targeting JIT Optimizer Heuristics : Presto는 몇몇 주요 연산에 대한 바이트코드를 생성한다. 생성기는 다음을 목표한다.
- 엔진이 별도 태스크에서 다른 스플릿 간 스위치한다면 JIT은 일반적인 루프 기반의 구현 최적화에 실패한다. 수집한 정보가 다른 태스크나 쿼리에서 필요없기 때문.
- 단일 태스크 파이프라인의 루프 내에서도 필요없는 루프 언롤링이나 인라인을 수행할 수 있다.
- 바이트코드 생성은 엔진의 중간 결과를 메모리가 아닌 CPU캐시나 레지스터에 저장하는 능력을 향상시킨다.
C. File Format Features
- Scan 오퍼레이터는 커넥터 API를 호출하고 Page라는 형대로 컬럼 기반 데이터를 받는다. 페이지는 Block의 리스트이며 각 블럭은 컬럼의 플랫 인메모리 표현이다. 플랫 메모리 자료구조는 성능상 이점이 있다. 특히 복합 타입, 포인터 추적, 언박싱, 가상 메서드 호출 등에서
- Presto는 파일 포맷의 커스텀 reader를 전달한다. 이는 파일 헤더나 푸터의 통계(min-max range header, Bloom filters)로 데이터 영역을 효과적으로 생략할 수 있다. 또한 커스텀 리더는 특정 형태의 압축 데이터를 블럭으로 직접 변환할 수 있다.
-
- 딕셔너리 인코딩 블럭은 low-cardinality 압축시 효과적이다. run-length 인코딩 블럭은 반복되는 데이터를 압축한다. 페이지 간 딕셔너리를 공유하면 메모리 효율적이다. ORC파일의 컬럼은 전체 stripe(수백만row)에 단일 딕셔너리를 사용 가능하다.
D. Lazy Data Loading
- Presto는 데이터의 지연 구체화를 지원한다. 이는 ORC, Parquet, RCFile등 컬럼 기반의 압축된 파일에 효과적이다. 커넥터는 cell에 실제로 접근할 때 데이터를 읽고 압축풀고 디코딩하는 lazy block을 생성할 수 있다. CPU시간의 대부분이 위 연산에 소요되고 필터는 매우 선택적이기 때문에 컬럼 접근이 잦지 않을 때 매우 효과적이다.
E. Operating on Compressed Data
- 변환이나 필터를 수행하는 페이지 처리기가 딕셔너리 블럭을 만나면 딕셔너리 내 모든 값을 처리한다(혹은 RLE 블럭의 단일 값). 때문에 전체 딕셔너리는 빠른 루프로 처리된다.
- 블럭 내 row수보다 딕셔너리 값이 많으면 페이지 프로세서는 참조되지 않은 값이 후속 블럭에서 사용될 것이라고 추측한다.
- 조인이나 집계에서 해시 테이블을 생성할 때도 딕셔너리 블럭 구조를 사용한다. 인덱스가 처리될 때 오퍼레이터는 해시 테이블의 위치를 기록해두고 후속 인덱스에서 재사용한다.
- Presto는 또한 실행 중에 중간 압축 결과를 생성한다. 예를 들어 조인 처리기는 효율적이라면 딕셔너리나 RLE 블럭을 생성한다.
- 해시 조인에서 probe측이 해시 테이블의 키를 룩업할때 실제 데이터를 복사하지 않고 값 인덱스를 배열에 기록한다. 오퍼레이터는 인덱스 리스트가 해당 배열인 딕셔너리 블럭을 생성한다. 해당 딕셔너리는 해시 테이블 내 블럭의 참조이다.(암튼 값 인덱스만 써서 복사 없이 조인한다는 뜻)
Performance
SKIP
Engineering Lessons
Presto의 디자인 철학
- Adaptiveness over configurability : Presto는 여러 쿼리 특성과 특성의 조합에 적응 가능해야 한다. 예를 들어 적응형 배압 적용 이전에 대부분의 메모리와 CPU는 적은 수의 잡에서 사용되었는데, 이는 동시에 실행되는 지연에 민감한 잡에 불리하게 작용한다. 적응성이 없다면 워크로드를 쪼개고 각각 설정을 조정해야 할 것이다. 결과적으로 상용에서 다양한 쿼리를 실행하도록 확장하기 어려울 것이다.
- Effortless instrumentation : Presto는 쿼리나 노드 수준에서 성능 통계를 노출한다. 이는 관측 가능한 시스템 설계를 권장하고 엔지니어가 코드의 성능을 계측하고 이해하도록 한다. 그 결과로 워커 노드는 10000개의 실시간 성능 카운터를 노출하고 오퍼레이터 수준의 통계를 수집하고 저장한다. (이를 태스크와 스테이지 수준으로 병합한다.) 결과적으로 시스템을 최적화 하는데 데이터-드리븐 접근을 할 수 있다.
- Static configuration : Presto와 같은 복잡한 시스템의 운영 이슈는 원인 분석과 빠른 완화가 어렵다. Presto는 정적 구성을 사용한다. 많은 수의 클러스터와 구성 집합이 있는 경우 복잡성을 운영적인 조사에서 배포 프로세스/tooling으로 옮기는 것이 효율적이다.
- Vertical integration : Presto 팀은 성능과 효율성이 중요한 컴포넌트를 위한 커스텀 라이브러리를 설계한다. 에를 들어 커스텀 파일 리더는 presto-네이티브한 자료구조를 사용하고 변환 오버헤드를 없앤다. 라이브러리를 쉽게 디버깅하고 통제하는 것 또한 매우 중요하다.
Conclusion
Presto. 오픈 소스 MPP(Massive Parrallel Processing) SQL 쿼리 엔진. Facebook에서 개발. 빠르게 큰 데이터셋을 처리한다. 다양한 유즈케이스에서 고성능 SQL 처리를 위해 유연하게 설계되었다. 풍부한 플러그인 인터페이스와 커넥터 API는 다양한 데이터 소스와 통합이 가능하다. 또한 적응성있게 설계되었다. 읽기/쓰기 병렬도, 네트워크 입출력, 오퍼레이터 휴리스틱, 스케줄링을 쿼리의 특성에 맞게 자동으로 조정할 수 있다. Presto의 아키텍처는 적은 지연시간을 요구하는 서비스 워크로드를 가능하게 하고 비싸고 오래 수행되는 쿼리를 효율적으로 처리한다.
Presto는 단일 SQL시스템으로 여러 분석 유즈케이스를 수행할 수 있게 한다. 여러 저장 시스템에 쉽게 쿼리하고 1000개 노드까지 확장 가능하다. 아키텍처와 설계는 붐비는 SQL-on-Bigdata 시장에서 틈새를 찾았다.
댓글남기기