고문헌 번역 프로젝트(3) - Transformer 적용
적용
업데이트:
개요
단순 LSTM seq2seq 모델이 처참한 결과를 보였다. 모델 뿐만 아니라 고유명사 전처리 등의 문제도 있겠으나, 일단은 표현력 부족을 해결하기 위해서 Transformer 모델을 적용해보았다.
Attention is All You Need : 자연어처리 지식이 전혀 없는 상태에서 읽어 무척이나 당황스러웠던 논문이었다. attention과 함께 self-Attention 기법을 적용한 Transformer 를 처음으로 선보였다.
Transformer
![]()
텐서플로우 공식문서에서 제공하는 코드를 대부분 참고해서 개발했다. 설명도 잘 나와있다.
처음에는 로컬에서 CPU로 모델 학습을 했는데, 끔찍한 학습 속도를 보여줬다.
그렇게 학습시킨 뒤 검증하려는데 그때서야 텐서 차원을 잘못 맞췄다는 걸 알았다.
이후 팀원이 GPU달린 서버를 제공해줘서 GPU로 모델 학습을 진행했다. 아주 빨랐다!
이전 RNN계열의 모델들은 입력 문장의 단어 순서대로 입력을 주기 떄문에 병렬 처리가 불가능하다. 따라서 GPU 프로그래밍이 불가능했다.
그러나! Transformer의 경우 병렬 연산이 가능하다. 따라서 GPU로 학습이 가능했다.![]()
결과
모델에 대한 자세한 설명은 생략하고, 결과를 말하자면. 급격한 성능 향상을 보였다.![]()
# 원문
○立義興親軍衛, 罷都摠中外諸軍事府。
(의흥친군위(義興親軍衛)를 설치하고 도총 중외 제군사부(都摠中外諸軍事府)를 폐지하였다.)
# 번역결과
'의/NNG', '흥/NNG', 'OOV', '의/NNG', '친/NNG', '군/NNG', '을/JKO', '세우/VV', '고/EC', '도/NNG', '총/NNG', '중/NNP', '의/JKG', '중외/NNG', '여러/MM', '군사/NNG', '를/JKO', '파하/VV', '았/EP', '다/EF', './SF'
마지막 decoder layer의 8개 heads의 attention을 살펴보면 다음과 같다.
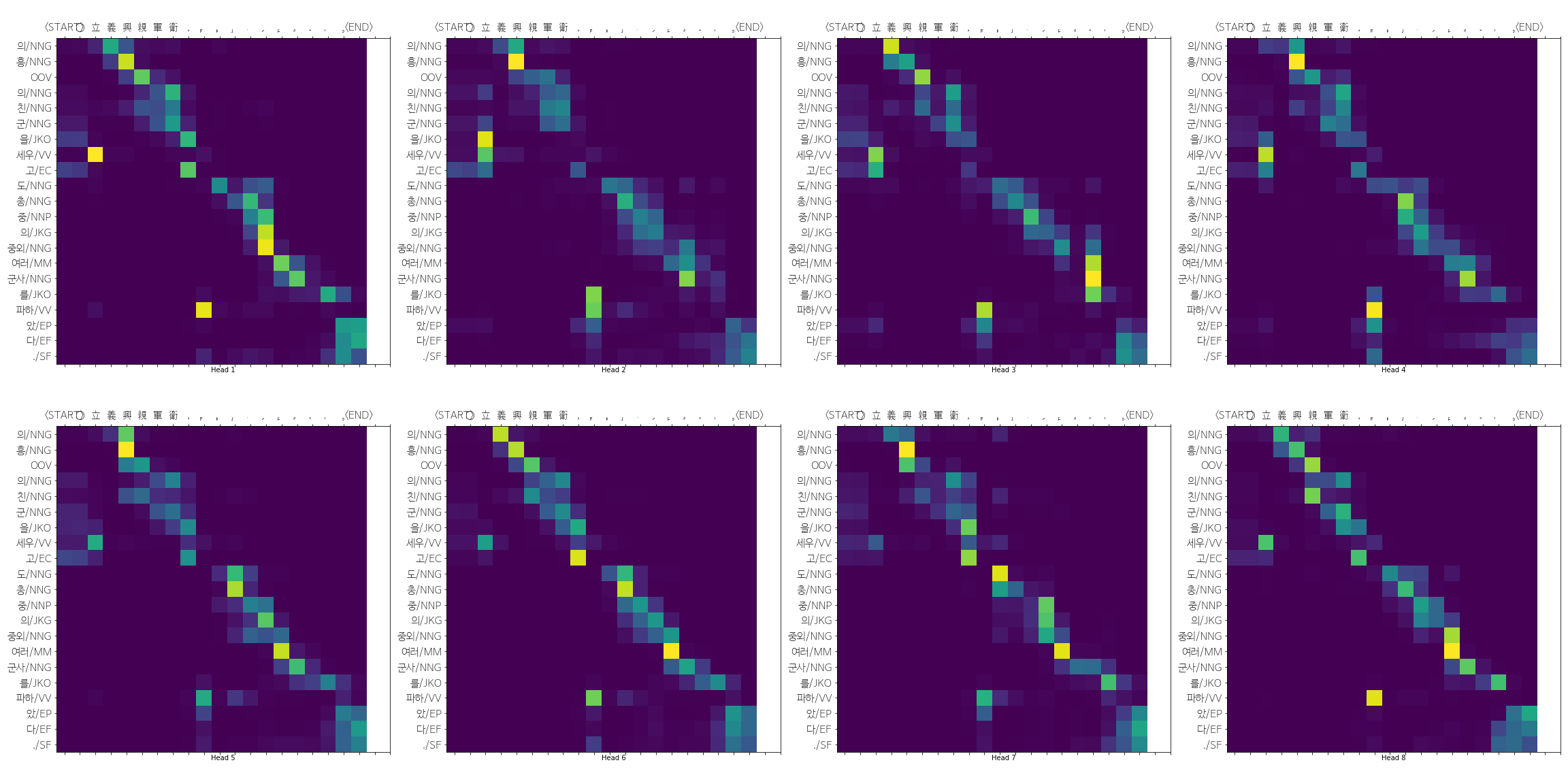
폰트가 깨져서 잘 보이지는 않지만, 立(세울 립) 이 (세우/vv) 형태소 토큰에 제대로 주목(attention)하는 것을 확인할 수 있다.
# 원문
○丁酉/雨。 前此久旱, 及上卽位, 霈然下雨, 人心大悅。
(비가 내리었다. 이보다 앞서 오랫동안 가물었는데, 임금이 왕위에 오르자 억수같이 비가 내리니, 백성의 마음이 크게 기뻐하였다.)
# 번역결과
비/NNG', '가/JKS', '내리/VV', '었/EP', '다/EF', './SF', '이/NP', '보다/JKB', '앞서/MAG', '오래/MAG', '가물/VV', '어서/EC', '임금/NNG', '이/JKS', '즉위/NNG', '하/XSV', '아/EC', 'OOV', '내리/VV', '어/EC', '비/NNG', '가/JKS', '내리/VV', '었/EP', '는데/EC', ',/SP', '인심/NNG', '이/JKS', '크/VA', '게/EC', '기쁘/VA', '어/EC', '하/VX', '았/EP', '다/EF', './SF'
이후 프로젝트 진행 주제는
- 고유명사들을 하나의 토큰으로 토큰화하는 전처리
- 전처리 파이프라인 구축하기
- Test 데이터셋 구축하여 Overfit 확인하며 학습하기
기술적으로 시도해볼 주제는
- 데이터를 Hadoop에 적재하여
- 데이터 파이프라인을 Haddop Ecosystem으로 구축해보기
등등이 있다.
댓글남기기