Database Internals - LSM Tree
업데이트:
출처
책 “Database Internals”, alex petrov
개요
- LSM 트리
- 대표적인 불변 자료 구조
- 수정 불가능
- 새로운 레코드는 새로운 파일에 추가
- 여러 버전의 파일 사본을 저장하며 최신 버전이 구 버전을 덮어씀
- 쓰기 성능이 좋음. 대상 레코드를 탐색하지 않아도 됨.
- 읽기 성능이 나쁨. 여러 버전의 파일을 읽고 조정해야 함.
Log-Structured Merged Tree
- 버퍼링과 추가 전용 구조를 이용하여 순차 쓰기(append)를 지원
- 트리의 모든 노드는 완전히 차 있으며 순차 접근에 최적화
- 이름은 log-structured filesystem에서 따옴
merged는 불변성을 유지하기 위해 트리를 merge sort하는 것을 의미- 중복된 복사본이 차지하는 공간을 확보하기 위한 작업(compaction)에 수행
- 읽기 요청 시 사용자에게 데이터 반환하기 전에 수행
- 파일 쓰기를 지연하고 변경 사항을 메모리 기반 테이블에 저장.
- 차후에 불변 디스크 파일에 저장해 변경 사항을 반영한다.
- 모든 레코드는 파일에 완전히 저장될 떄까지 메모리를 통해 참조 가능한 상태로 유지
- 순차 읽기에 적합.
- 불변 파일이기 때문.
- 디스크에 single path로 저장하고, 파일은 추가 전용 구조이다.
- 연속된 공간에 저장하므로 디스크 단편화 방지
- 향후에 추가될 데이터를 위한 공간 또는 업데이트된 레코드가 원본 레코드보다 큰 경우를 위한 공간을 미리 할당하지 않아도 됨. -> 밀도가 높다.
- 쓰기 성능과 처리량 향상
- 불변 파일이기 떄문.
- 삽입, 수정, 삭제 시에 탐색이 필요 없음
- 대신 중복 저장을 허용하고 충돌은 읽기 작업 중에 해결.
- 읽기보다 쓰기가 많은 애플리케이션에 적합.
- 읽기 작업이 적은 수의 파일을 읽도록 파일을 병합하고 재작성해야 함.(compaction)
LSM 트리 구조
작은 메모리 기반 컴포넌트(버퍼) + 큰 디스크 기반 컴포넌트
메모리 기반 컴포넌트 memtable
- 불변 자료 구조
- 임계값에 도달하면 디스크로 flush
- 업데이트 시 디스크에 접근하지 않기에 disk I/O 없음
- WAL(Write Ahead Log)를 유지해 레코드의 지속성을 보장
- WAL에 추가 -> 메모리에 커밋 -> 클라이언트에게 반환
- 메모리에 동시 접근을 지원하는 정렬된 자료 구조 형태를 유지.
디스크 기반 컴포넌트
- 읽기 작업에만 사용됨. LSM 트리의 기본 작업
- 인메모리 테이블에 쓰기
- 디스크와 메모리 기반 테이블에서 읽기
- 병합
- 파일 삭제
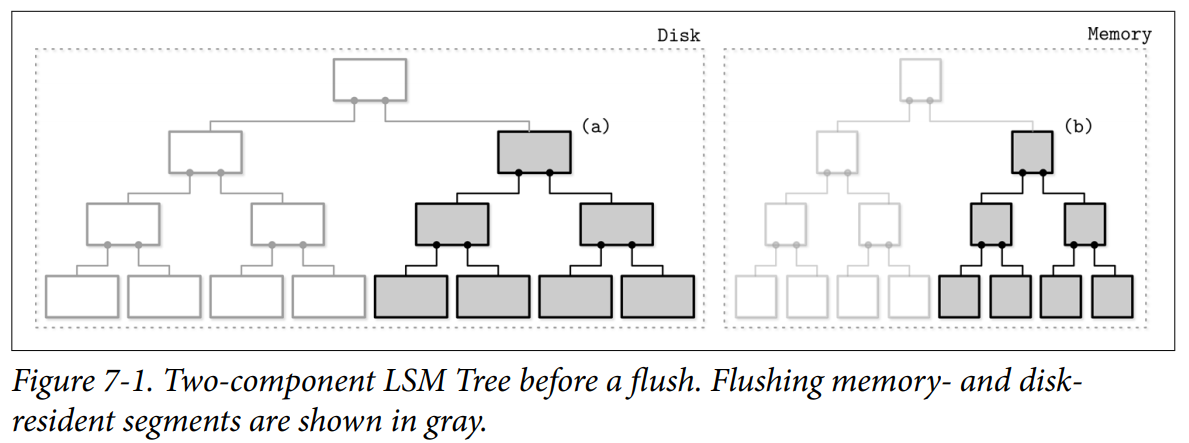
이중 컴포넌트 LSM 트리
- 단일 디스크 기반 컴포넌트
- 100% 채워진 노드와 읽기 전용 페이지로 구성된 B-Tree
- 플러시 과정
-
인메모리 서브트리별로 디스크에서 해당 서브트리를 찾아 병합하고 새로운 세그먼트에 저장
-
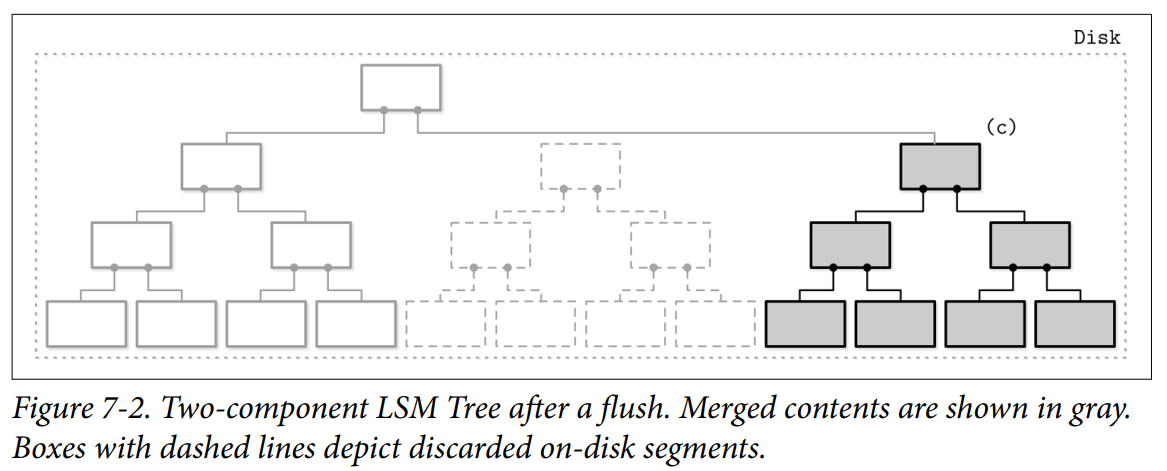
기존 인메모리와 디스크 기반 서브트리는 삭제되고 병합된 서브트리로 대체
-
- 병합 작업 O(N)
- 디스크 트리와 인메모리 트리를 순회하면서 값을 비교
- 두 트리 모두 정렬되었기에 병합 결과도 순서가 보장.
- 중복된 레코드가 있다면 최신 값을 선택
- 주의점
- 플러시 시점 이후의 모든 새로운 쓰기요청은 새로운 멤테이블에 저장한다
- 플러시 중에도 읽기 작업은 디스크와 인메모리 트리에 접근 가능해야 함
- 플러시 완료되면 ‘병합된 트리(c)를 접근 가능한 상태로 만드는 작업’ 과 ‘(a)(b)를 삭제하는 작업’은 원자적 수행되야함
이중 컴포넌트 LSM트리의 사용 사례는 거의 없다. 플러시할때마다 병합해야하니 쓰기 증폭이 생긴다.
다중 컴포넌트 LSM 트리
멤테이블 전체를 한 번에 플러시
- 디스크에 테이블이 다수 생성.
- 데이터를 찾기 위해 여러 파일을 읽어야함. 비용 많아짐
- 백그라운드에서 파일 병합 작업(compaction)을 주기적으로 수행
- 여러 테이블을 읽고 병합한 뒤 새로운 파일에 결과를 저장
- 기존 테이블은 삭제
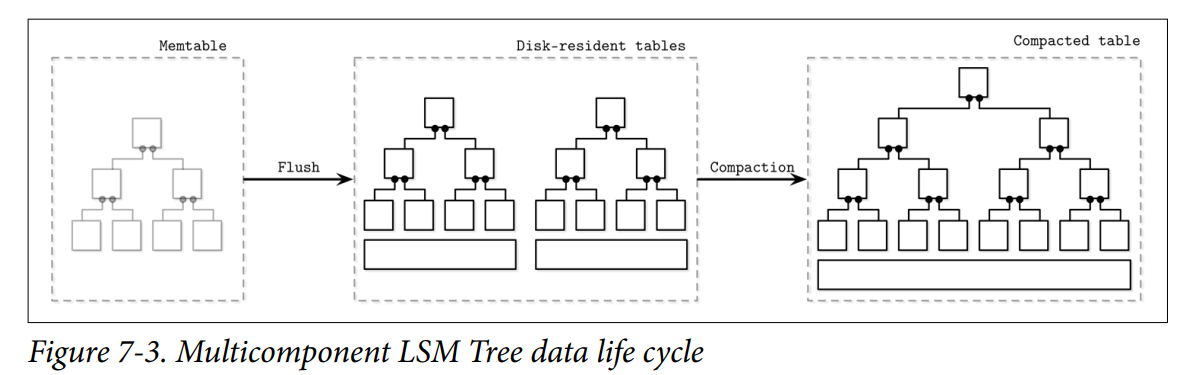
- 메모리 기반 컴포넌트(멤테이블)에 버퍼링
- 버퍼의 크기가 임계값에 도달하면 플러시
- 컴팩션을 통해 파일 개수를 줄이고 큰 테이블로 병합
인메모리 테이블
- 플러시는 일정 시간 주기 혹은 임계 크기에 도달하면 발동.
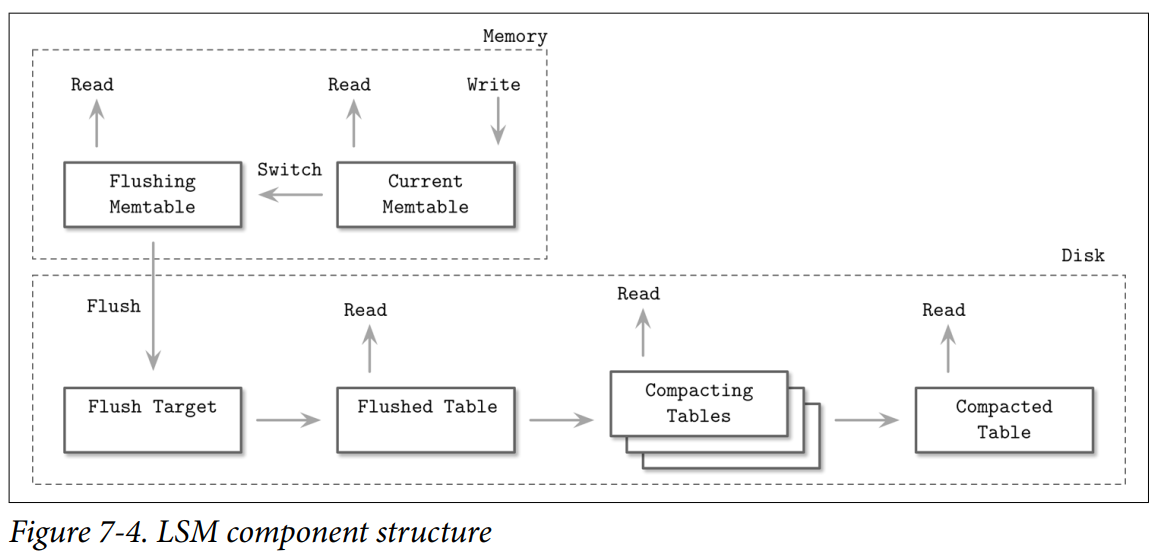
- 새로운 멤테이블을 할당해 이후 들어오는 쓰기를 담당. 기존 테이블은 플러시.
- 두 단계의 작업은 원자적이어야 함.
- 플러시 진행 동안 플러시 대상 멤테이블과 최신 멤테이블 모두 읽을 수 있다.
- 플러시 완료시까지 유일하게 해당 내용이 디스크에 저장된 곳은 WAL.
- 플러시 완료되면 로그에서 대상 멤테이블과 관련된 부분은 삭제.
수정과 삭제
다른 디스크 또는 인메모리 테이블에 동일한 키에 대한 데이터가 존재할 수 있다. 때문에 멤테이블에서 레코드를 삭제하는 것만으로는 영향이 없거나 이전 값을 되살릴 뿐이다.
- 플러시 완료되면 로그에서 대상 멤테이블과 관련된 부분은 삭제.
- ex)
r1 = <k, v1>in disk,r2 = nullin memtable- 결과
r = <k, v1>따라서 삭제 내역을 tombstone으로 기록한다.
- 결과
- ex)
r1 = <k, v1>in disk,r2 = <k, tombstone>in memtable- 결과
k는 삭제됨.연속된 키 범위를 삭제하는 방법도 있다.
- 결과
- range tombstone
- 카산드라는 이 방식으로 동작

k2와k3는 결과에서 배제된다.LSM 트리 룩업
LSM트리는 여러 컴포넌트로 구성
- 결과 반환 전에 병합하고 조정해야 함
병합-반복
디스크 테이블은 정렬되 있어서 다방향 병합 정렬을 사용할 수 있다.
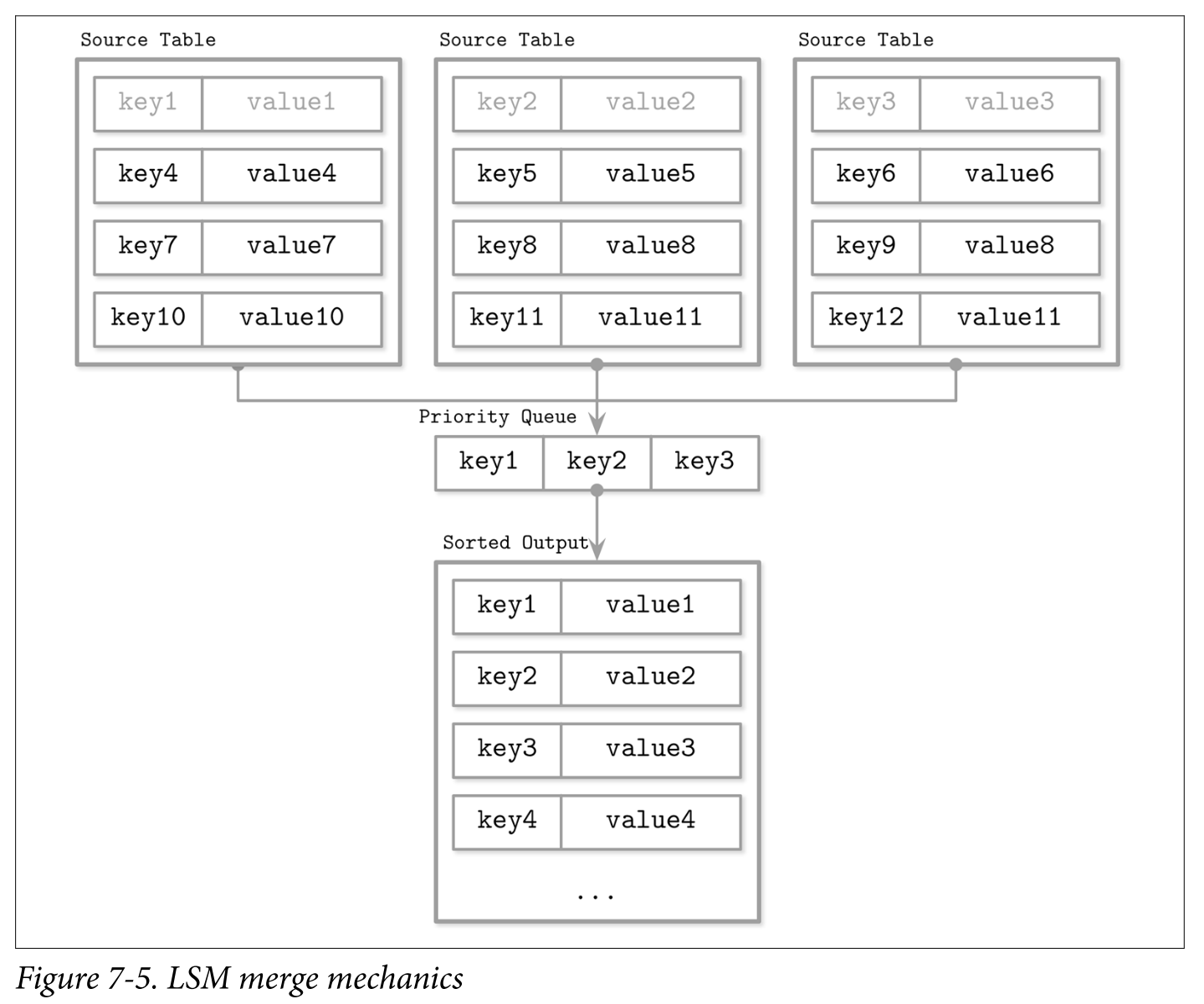
- 반복자의 헤드 원소로 우선순위 큐를 채운다
- 큐에서 가장 작은 값(헤드)를 선택한다
- 해당 반복자에 원소가 남아 있을 경우 다음 원소를 큐에 추가한다
조정
같은 키에 대한 여러 값 사이의 충돌 해결 및 조정 단계
- 여러 테이블에 같은 키에 대한 업데이트 / 삭제 내역이 있다면 조정이 필요
- 동일한 키의 레코드 중 더 높은 타임스탬프의 레코드만 클라이언트에게 반환
LSM 트리 유지보수
주기적인 컴팩션을 통해 증가하는 디스크 테이블의 수를 줄인다.
- 컴팩트 대상 테이블은 컴팩션 완료 시까지 읽을 수 있음
- 디스크에 컴팩트된 테이블을 쓸 수 있을 만큼 충분한 공간이 확보되야 함
컴팩션을 통해 여러 테이블이 하나로 병합되거나 하나의 테이블이 여러 테이블로 나눠질 수 있다.
컴팩션 과저에서 툼스톤을 바로 삭제하지 않고 유예기간을 둔다.
- 과거 데이터의 부활을 방지하기 위함.
레벨형 컴팩션
- RocksDB에서 사용 - 디스크 테이블을 여러 레벨로 나눈다
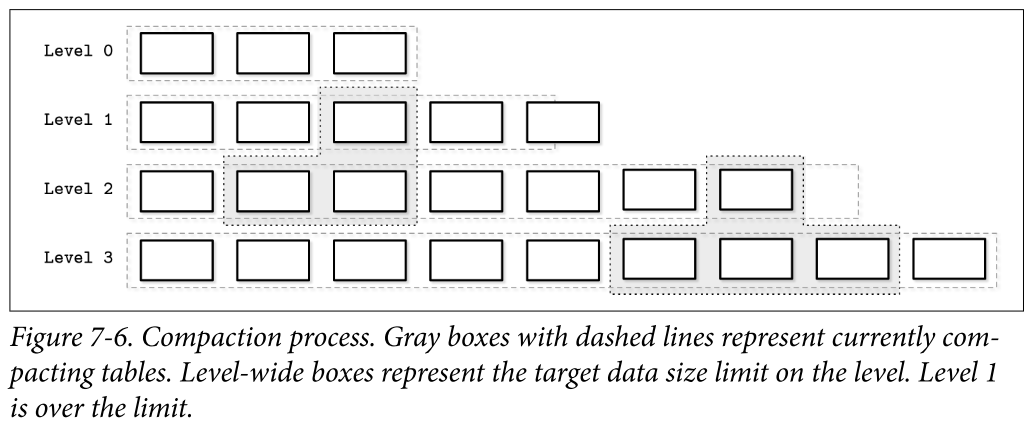
- 플러시하면 0번 레벨의 테이블이 생성
- 0번 레벨 테이블의 키 범위는 겹칠 수 있다
- 테이블 수가 일정 수에 도달하면 데이터를 병합해 다음 레벨 테이블을 생성
- 1번 이상의 레벨 테이블은 키 범위가 겹치지 않는다.
- 읽기 시 열어야 하는 테이블의 수가 준다.
- 검색 대상 키가 테이블 키 범위 안에 있는 경우의 테이블만 조회
- 1번 이상의 레벨 테이블은 키 범위가 겹치지 않는다.
- 각 레벨의 테이블 크기와 수는 제한되어 있다.
- 초과시 범위가 겹치는 다음 레벨의 테이블과 병합
크기 단계별 컴팩션
테이블의 크기를 기준으로 디스크 테이블을 그룹화
- 초과시 범위가 겹치는 다음 레벨의 테이블과 병합
- 0번 레벨에는 가장 작은 크기의 테이블
- 컴팩트된 테이블은 같은 크기의 테이블이 저장된 레벨에 저장
타임 윈도우 컴팩션
- 카산드라에서 옵션으로 제공
- 유효 기간이 있는 데이터(TTL)를 처리하는 시계열 워크로드에 특화된 방법
- 컴팩션하지 않고도 데이터가 쓰여진 시간을 참고해 파일을 한번에 삭제할 수 있다.
카산드라는 세 개의 컴팩션 전략을 선택할수 있게 지원함. 기본은 크기 단계별 컴팩션. 참고
Picking the right compaction strategy for your workload will ensure the best performance for both querying and for compaction itself.
Size Tiered Compaction Strategy (STCS)The default compaction strategy. Useful as a fallback when other strategies don’t fit the workload. Most useful for non pure time series workloads with spinning disks, or when the I/O fromLCSis too high.
Leveled Compaction Strategy (LCS)Leveled Compaction Strategy (LCS) is optimized for read heavy workloads, or workloads with lots of updates and deletes. It is not a good choice for immutable time series data.
Time Window Compaction Strategy (TWCS)Time Window Compaction Strategy is designed for TTL’ed, mostly immutable time series data.
읽기, 쓰기, 메모리 공간 증폭
데이터를 디스크에 불변 방식으로 저장할 때 다음 문제가 생긴다.
- 읽기 증폭 데이터를 읽기 위해 여러 테이블을 참조하면서 발생
- 쓰기 증폭 컴팩션 과정에서 발생하는 연속된 재작성으로 인해 발생
- 공간 증폭
같은 키에 대해 여러 레코드가 존재할 때 발생
RUM 예측
Read, Update, Memory 오버헤드를 기준으로 비용을 계산하는 비용 모델
- 세 가지 오버헤드 중 두 개를 줄이면 나머지가 불가피하게 증가한다.
- 한 가지를 희생할 수밖에 없음. 트레이드 오프 B-트리는 읽기에 최적화
- 쓰기 시 디스크에서 레코드를 찾고, 디스크 페이지를 여러 차례 업데이트 - 쓰기 오버헤드
- 향후 업데이트를 위한 공간, 삭제된 공간 - 공간 오버헤드 LSM트리는 쓰기에 최적화
- 쓰기 시 레코드를 찾지 않음. 향후 쓰기를 위한 공간 할당하지 않음
- 중복 데이터 - 메모리 오버헤드
- 읽기 시 조정 과정 - 읽기 오버헤드
세부 구현 설명
SSTable
디스크 기반 테이블의 구현체.
- 레코드를 키 순서로 정렬해 저장한다.
- 인덱스 파일 + 데이터 파일 인덱스 파일
- B-트리 또는 해시 테이블로 구현
- 키와 데이터(데이터 파일에 실제 데이터의 위치 오프셋)로 구성 데이터 파일
- 키 순서로 정렬됨
- 연결된 키-값 쌍으로 구성
데이터 레코드는 정렬되어 있으므로 컴팩션 시 인덱스 파일에 접근하지 않아도 됨.
SSTable 첨부형 보조 인덱스 (Secondary Index)
- 카산드라의 구현체
- 기본 키 이외 다른 필드로 테이블을 인덱싱 가능
- 인덱스 자료구조와 이들의 수명 주기를 SSTable의 수명 주기와 동기화하고 SSTable별로 인덱스 생성
- 플러쉬 하면 SSTable 기본키 인덱스와 함께 보조 인덱스 파일도 생성
- LSM트리는 데이터를 버퍼에 저장하기 떄문에 인덱스는 메모리와 디스크 기반 테이블을 모두 인덱싱해야 함
- 멤테이블을 인덱싱하는 인메모리 자료구조를 별도로 생성
- 레코드가 요청되면 여러 인덱스를 참조해 해당 레코드의 기본 키를 찾고, LSM트리 룩업과 유사하게 병합 및 조정
HBase는 secondary index를 지원하지 않음. 카산드라의 큰 장점인 듯.
블룸 필터
읽기 시 여러 디스크에 저장된 테이블에 접근해야 한다. 블룸 필터는 읽기 증폭을 최적화하기 위한 방법
- 특정 원소가 집합에 속하는지 여부를 확인할 수 있는 공간 효율적인 확률적 자료구조
- false-positive는 발생하지만 false-negative는 발생하지 않음
- 특정 키가 테이블에 존재할 수 있는지 또는 확실히 존재하지 않는지 알 수 있음
- 읽기 시 접근해야 할 테이블의 수를 줄인다.
 구현
구현
- 큰 비트 배열과 여러 해시 함수를 사용(위 그림에서는 해시 함수가 3개)
- 각 레코드의 키를 해싱. 비트 배열에서 인덱스를 찾고 비트를 1로 설정
- 1로 설정된 비트는 일부 해시 함수가 일부 키에 해당 비트 위치를 할당했다는 것.
- 레코드 확인 시 모든 해시 함수의 해싱 결과 인덱스의 비트가 1이면 해당 키는 집합에 속할 수 있다(테이블에 존재할 수 있다.)
- 단 한개의 비트라도 0이라면 확실히 집합에 속하지 않는다(테이블에 확실히 없다.)
- 비트 배열의 크기가 클수록
- 해시 충돌(레코드의 해시 결과 인덱스가 같은 경우)이 줄어든다. false positive 정확도 증가
- 더 많은 메모리.
- 해시 함수가 많을수록
- 더 많은 비트를 확인 가능. false positive 정확도 증가
- 해시 연산 많아져 성능 낮아짐.
댓글남기기